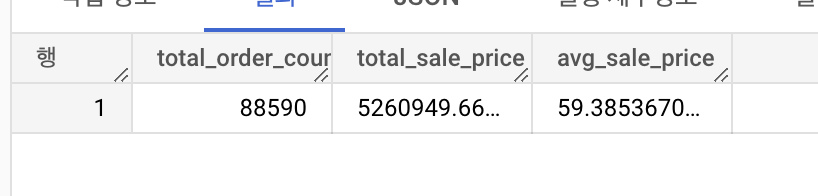
순서 1. 순서형인지 연속형인지 범주형인지 2. 독림표본이나 대응표본이냐 3. 그런데 좀 특이하게 분산분석이 들어간다 독립표본 t: 두 집단의 평균 비교 대응표본 t: 두 집단의 자료를 쌍으로 묶을 수 있을 때 차이의 평균 비교 맨-휘트니 U 검정: 두 집단의 순서형 변수를 비교 a, b 집단 비슷할 때 순서 a, b, a, b 이렇게 서고 집단이 안 비슷하면 a,a,a b,b,b 이렇게 되면 귀무가설 기각(밑 이미지 참고) 줄을 섰는데 튀는 데이터가 있어도 순서대로 서기만 하면 되니까 큰 문제가 되지 않음, 극단치 있어도 쓸 수는 있다 분산 분석: 셋 이상 집단의 평균 비교 카이제곱 적합도 검정: 관찰된 빈도가 기대되는 빈도와 일치하는지 확인 카이제곱 독립성 검정: 두 범주 변수 간에 관계가 있는지 맥..