- Tidy-data: 깔끔한 데이터(= 각 변수가 열이고, 관측치가 행이 되도록 배열된 데이터)
- 데이터분석 위해서 데이터를 깔끔한 형태로 만들어주는 것이 중요
- 정리가 잘 된 데이터 ≠ 깔끔한 데이터 -> 국가통계데이터포털에서 제공하는 데이터(과거)
-> pd.melt 사용

- 열에 있던 데이터를 행으로 녹인다
- 관측치가 행이고 변수가 열이 되는 것
- 깔끔한 데이터는 각 변수는 개별 열에, 각 관측치는 개별 행에, 관측 구성 요소 각각 값은 테이블 안에 위치
- id_vars는 변하지 않는 칼럼(기준 칼럼)
- value_vars가 2개 이상 필요로 할 때는 id_vars 반복될 수 있음 -> melt되는 칼럼의 숫자가 늘어날수록 기준점은 그만큼 반복 할당

https://seong6496.tistory.com/243
[Pandas] 데이터프레임 재구조화(Melt)
파이썬에서는 판다스로 주로 데이터 전처리를 합니다. 판다스에서 데이터 전처리의 중요한 요소인 재구조화(reshaping) 방법에는 pivot과 stack, unstack이 있고 melt라는 것도 있습니다. 앞선 포스팅에
seong6496.tistory.com
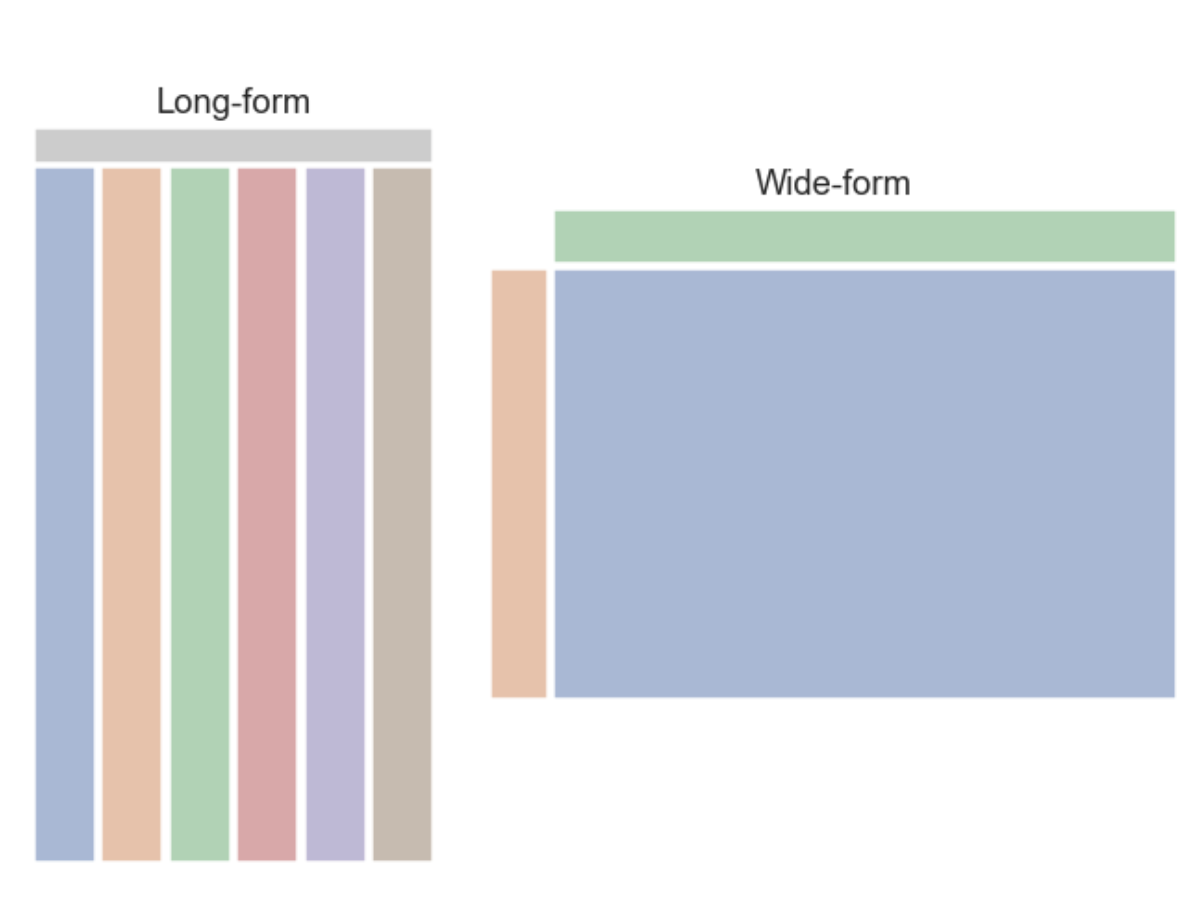
- wide from: pandas plot()으로 막대의 색상을 다르게 지정하거나 서브플롯을 그리거나 시각화 하기에 좋음
- long form: 변수(ex 연도, 월별)에 따라 x, y, hue(color), column 등을 지정해서 사용하기 좋음
데이터셋
- 전국 평균 분양가격(2013년 9월~2015년 8월)
: 전국 공동주택의 3.3제곱미터당 평균분양가격 데이터를 제공
- 주택도시보증공사 전국 평균 분양가격(2015년 10월~)
: 전국 공동주택의 연도별, 월별, 전용면적별 제곱미터당 평균분양가격 데이터를 제공 / 지역별 평균값은 단순 산술평균값이 아닌 가중평균값임
라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'데이터 로드
from glob import glob
file_name = glob('data/apt*.csv')
df_last = pd.read_csv(file_name[0], encoding='cp949')
df_last.head()- data/apt 로 시작하는 데이터 찾기

2013년 9월 ~ 2015년 8월까지 데이터 로드
- 전국 평균 분양가격(13년 9월 ~ 15년 8월)파일을 불러오고 df_first 변수에 담기
file_name
df_first = pd.read_csv(file_name[1], encoding = 'cp949')
df_first.shape
>> (17, 22)df_first.head(2)
데이터 요약 info
df_last.info()
df_first.info()
결측치
- isnull 혹은 isna를 통해 데이터가 비어있는지를 확인
- 결측치는 True로 표시 -> True == 1 이기 때문에 이 값을 다 더해주면 결측치의 수가 됨
print(df_last.isnull().sum())
print(df_last.isnull().mean())

-> 결측치의 합계와 비율
- 모든 연도월에 분양이 없을 수도 있음 특히 지방의 경우 분양이 없는 기간이 생길 수도 있음
데이터 타입 변경
- 분양가격 object(문자)타입
- 문자열은 계산할 수 없음 -> 수치 데이터로 변경
- df_last['분양가격']에는 ' '가 섞여있어서 바로 .astype(float) 할 수 없음 -> nan 값 넣어주고 변환
df_last['분양가격'].replace(' ', np.nan).astype(int)방법 1
df_last['분양가격'] = pd.to_numeric(df_last['분양가격'],errors = 'coerce')
df_last['분양가격'].info()방법 2

errors = 'coerce
errors{‘ignore’, ‘raise’, ‘coerce’}, default ‘raise’
- If ‘raise’, then invalid parsing will raise an exception.
- If ‘coerce’, then invalid parsing will be set as NaN.
- If ‘ignore’, then invalid parsing will return the input.
https://pandas.pydata.org/docs/reference/api/pandas.to_numeric.html
pandas.to_numeric — pandas 1.5.3 documentation
Can be ‘integer’, ‘signed’, ‘unsigned’, or ‘float’. If not None, and if the data has been successfully cast to a numerical dtype (or if the data was numeric to begin with), downcast that resulting data to the smallest numerical dtype possib
pandas.pydata.org
평당분양가격 구하기
- KOSIS에 올라와 있는 13년도부터 15년까지의 데이터는 평당분양가격이 기준이 됨
- 데이터를 병합해서 사용하려는데 가격의 기준이 다르면 분석이 제대로 되지 않음
- 기준을 맞춰주기 위해 기존 제곱미터당 분양가격에 * 3.3 을 하면 평당 분양가격
df_last['평당분양가격'] = df_last['분양가격'] * 3.3
df_last
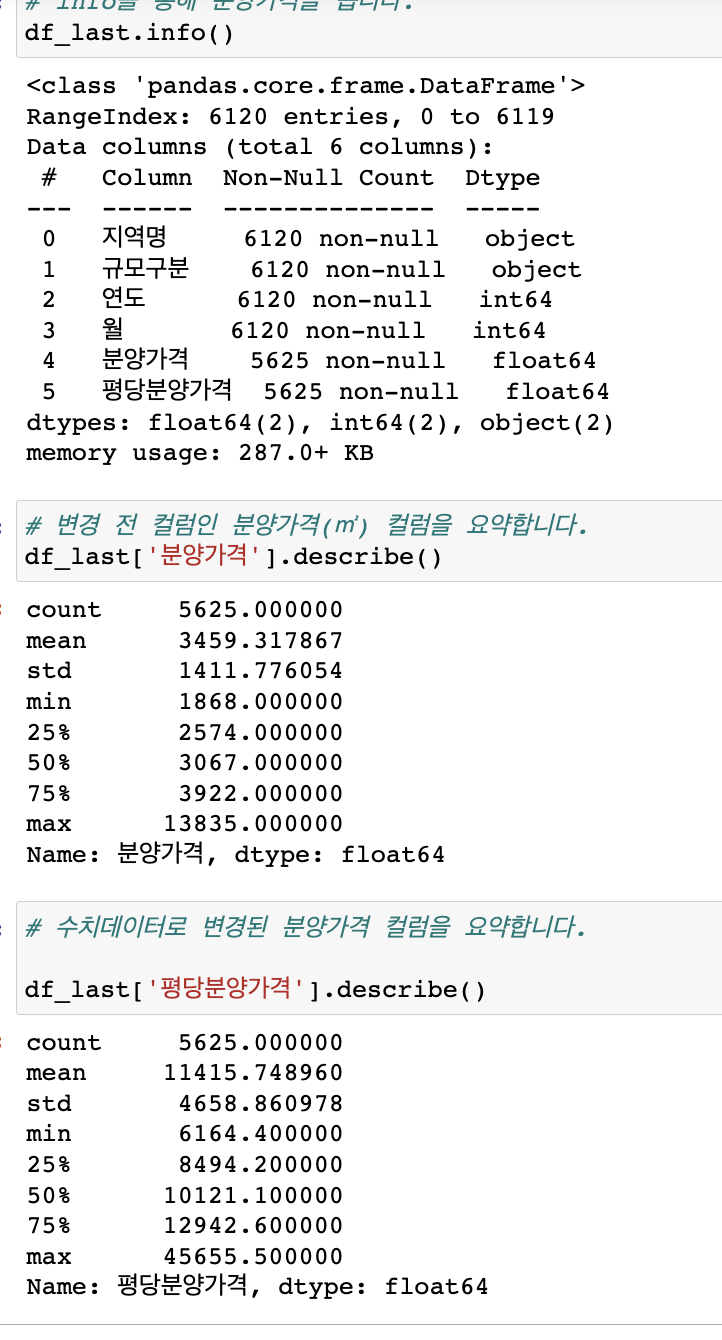
분양가격 요약
규모구분을 전용면적 칼럼으로
- 규모구분 칼럼은 전용면적에 대한 내용
- 전용면적이라는 문구가 공통적으로 들어가고, 전용면적이 조금 더 직관적임 -> 전용면적이라는 칼럼 새로 -> 기존 규모구분의 값에서 필요 없는 문구 제거
- 중복 데이터 많은면 용량 그만큼 늘어남 -> 연산 및 처리속도 오래 걸림 -> 정리
df_last['전용면적'] = df_last['규모구분'].str.replace('전용면적 |제곱미터|이하', '', regex = True)
df_last['전용면적'] =df_last['전용면적'].str.replace('초과', '~')
df_last
- replace: 데이터프레임에만 사용가능 (regex = True) 를 하지 않으면 완전히 일치하는 데이터에서만 변경 -> | 정규표현식
- str.replace: 시리즈에만 사용가능, 일부만 일치해도 변경 가능
필요없는 칼럼 제거
- 필요없는 칼럼 지우기
- df.drop(['a', 'b'], axis = 1) -> axis = 0 이 디폴트: 행을 지움
- df.drop(columns = ['a', 'b'])
df_last = df_last.drop(columns = ['규모구분', '분양가격'])
df_last.info()
-> 메모리 줄어들음
최근 데이터 시각화 하기
수치데이터 히스토그램
df_last.hist(figsize=(8, 6), bins = 50)

- 연도, 월 숫자지만 -> 범주형
- 평당 분양가격 1천 아래에 몰려있음 -> 4천같이 이상치도 있음
- 숫자 형태의 값을 가져도 데이터의 의미상 수학적 계산이 무의미한 경우 변수를 범주형 변수로 활용
- 나이의 경우 숫자이지만 더하기 빼기 등 수학적 계산이 사실상 무의미하므로 범주형 변수로 활용
sns.pairplot(df_last, hue = '지역명', corner= True)
- pairplot은 여러개의 '수치형' 변수를 짝을 지어 표현하기 적합
- seaborn 서브플롯에서는 figsize 동작하지 않음
- height = 2.5, aspect = 1 로 상대값 지정해서 조정
- corner = True 로 같은 값인 대각선 위의 값을 날림
- hue = '지역명' -> 지역명에 따라 다른 색상으로 표기하겠다
2015년 8월 이전 데이터 보기
- columns이 많은데 그냥 치면 생략됨 가운데 -> 다 보고싶으면 pd.options.display.max_columns = None
- 몇개만 보고싶으면 = 10
- 이렇게 하면 노트북 느려질 수 있음
df_first.head(2)
melt로 Tidy data 만들기
- df_first 와 df_last 데이터 프레임이 모습이 달라서 같은 형태로 만ㄷ르어 주어야 데이터 합칠 수 있음
- 합치기 위해 melt를 사용해 열에 있는 데이터를 행으로 녹여봅니다

df_first_melt = pd.melt(df_first, id_vars = '지역')
df_first_melt.head(3)
df_first_melt.columns = ['지역명', '기간', '평당분양가격']
df_first_melt
연도와 월을 분리
- pandas의 string-handling 사용
date = "2013년12월"
date.split('년')
>> ['2013', '12월']
int(date.split('년')[0])
>> 2013
date.split('년')[1].replace('월', '')
>> '12'- 이전에 replace()는 일붐나 일치하면 변경이 되지 않고 전체가 일치되어야 변경 가능하다고 했는데 왜 일부만 일치하는데도 변경이 될까? -> 메서드 명이 같더라도 python string의 메서드인지, pandas의 데이터 프레임의 메서드인지에 따라 다르다
연도 반환하는 함수 -> int
def parse_year(date) :
return int(date.split('년')[0])월 반환하는 함수 -> int
def parse_month :
return int(date.split('년')[1].replace('월',''))-> date.split('년')[1]까지 하면 '12월'이 반환 -> 월 없애기 위해 replace
함수를 활용하여 파생변수 만들기
df_first_melt['연도'] = df_first_melt['기간'].apply(parse_year)
df_first_melt['월'] = df_first_melt['기간'].apply(parse_month)
df_first_melt
-> 왜 apply? map은?
: map은 단일 칼럼이나 시리즈에서만 가능
str.split을 사용하여 파생변수 만들기
df_first_melt["연도"] = df_first_melt["기간"].str.split("년", expand=True)[0].astype(int)
df_first_melt["월"] = df_first_melt["기간"].str.split("년", expand=True)[1].str.replace("월", "").astype(int)- expand = True 데이터 프레임으로 만들겠다는 의미
df_first_melt.columns
>> Index(['지역명', '기간', '평당분양가격', '연도', '월'], dtype='object')
df_last.columns
>> Index(['지역명', '연도', '월', '평당분양가격', '전용면적'], dtype='object')- 두 데이터프레임을 합치려면 칼럼의 이름이 같아야 함
cols = ['지역명', '연도', '월', '평당분양가격']
df_last_prepare = df_last.loc[df_last['전용면적'] == '모든면적', cols].copy()
df_last_prepare.head()
- 최근 데이터가 담긴 df_last에는 전용면적이 있음
- 이전 데이터에는 전용면적이 없기 때문에 '모든면적'인 것만 사용하도록 한다
- loc를 사용해 모든면적에 해당하는 것만 copy로 복사
df_first_prepare = df_first_melt[cols].copy()
df_first_prepare.head()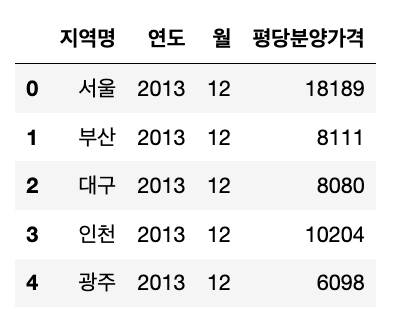
concat으로 합치기
df = pd.concat([df_first_prepare, df_last_prepare])
df.tail()
df['연도'].value_counts().sort_index()
- value_counts()는 시리즈에서만 !
groupby로 데이터 집계하기
https://rfriend.tistory.com/276
[Python pandas] 데이터 재구조화(reshaping data) : pd.DataFrame.stack(), pd.DataFrame.unstack()
데이터 재구조화(reshaping data)를 위해 사용할 수 있는 Python pandas의 함수들에 대해서 아래의 순서대로 나누어서 소개해보겠습니다. - (1) pivot(), pd.pivot_table() - (2) stack(), unstack() - (3) melt() - (4) wide_to_
rfriend.tistory.com
yprice = df.groupby(['연도', '지역명'])['평당분양가격'].mean().unstack()
yprice.iloc[:5, :5]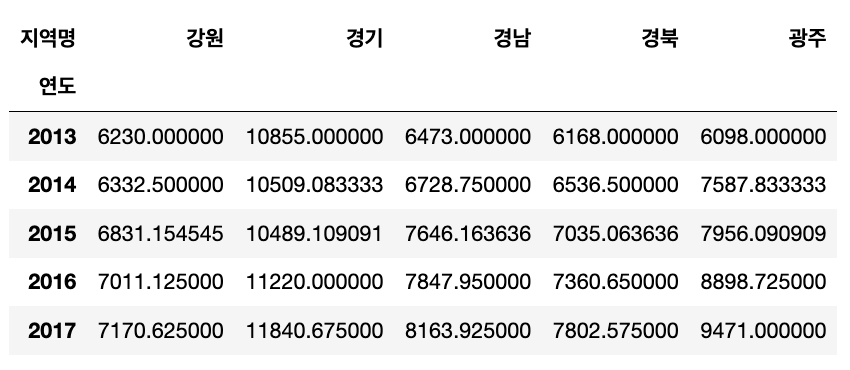
df.groupby(["인덱스로 사용할 컬럼명"])["계산할 컬럼 값"].연산()
df.groupby(['지역명'])['평당분양가격'].mean().sort_values(ascending = False).plot(kind = 'bar', grid = True, rot = 60)
yprice[['서울', '경기', '제주']].plot(figsize = (12, 4))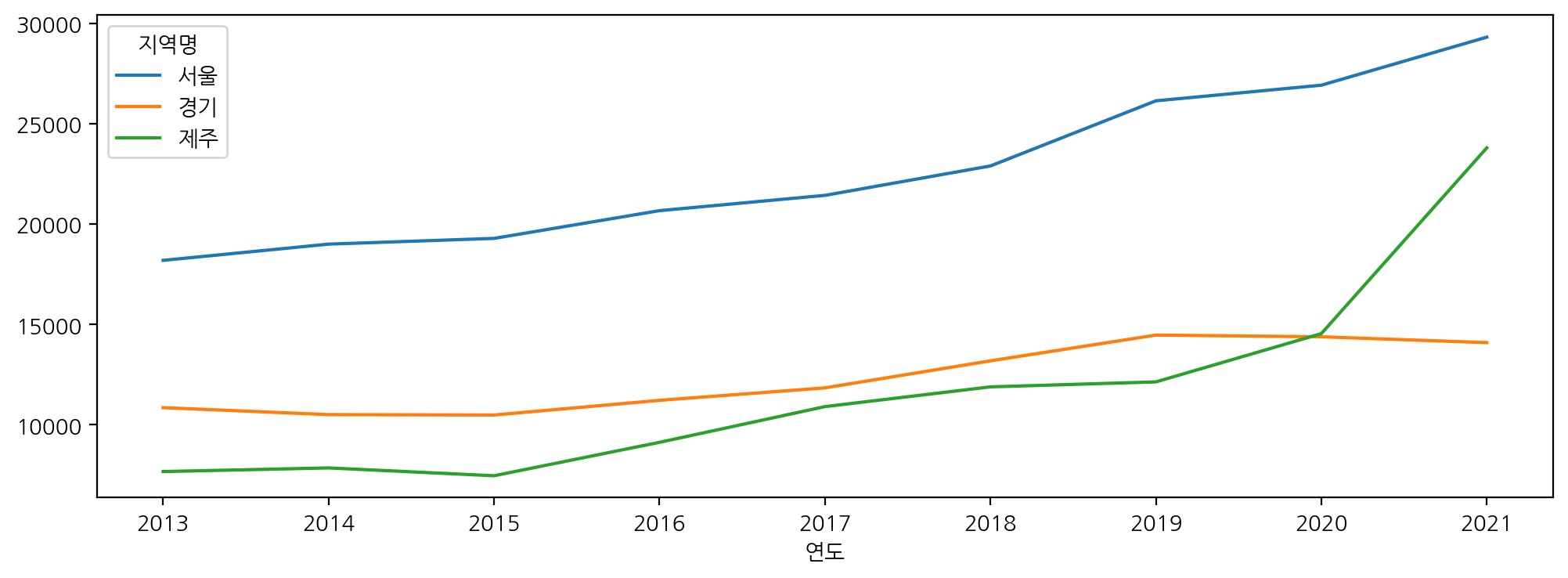
- 연도, 지역명으로 평당분양가격 평균 구하기
pivot table로 데이터 집계하기
- groupby 로 했던 작업을 pivot_table로 똑같이 해보기
- 지역명을 index로, 평당분양가격을 values로
region_price = pd.pivot_table(df, index = '지역명', values = '평당분양가격') #알아서 평균 구함
region_price.head()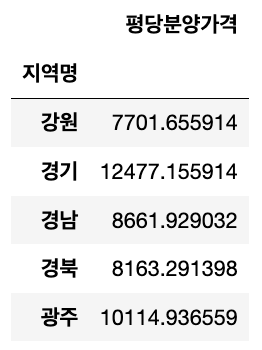
region_price.sort_values('평당분양가격').plot(kind = 'barh')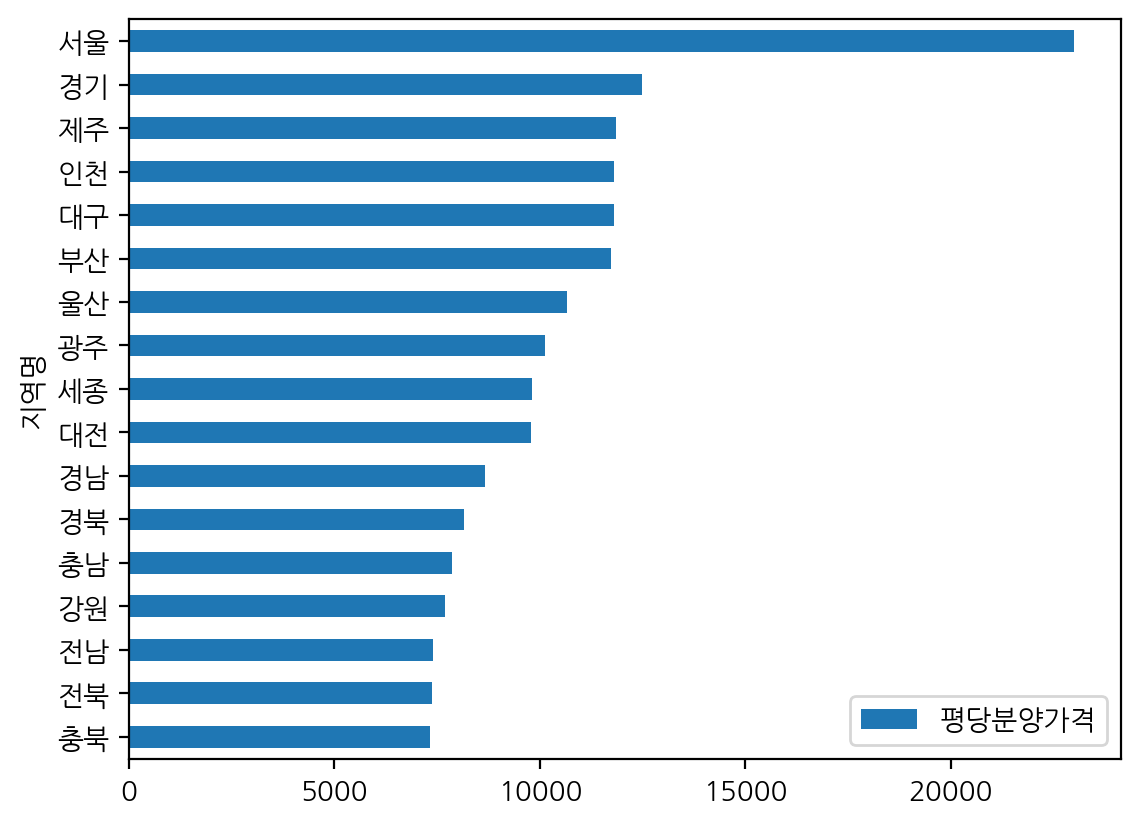
- 연도, 지역명으로 평당분양가격의 평균을 구함
pivot_year_price = df.pivot_table(
index = '연도',
columns = '지역명',
values = '평당분양가격')
plt.figure(figsize = (12, 6))
sns.heatmap(pivot_year_price, cmap = 'Blues', annot = True, fmt = ',.0f')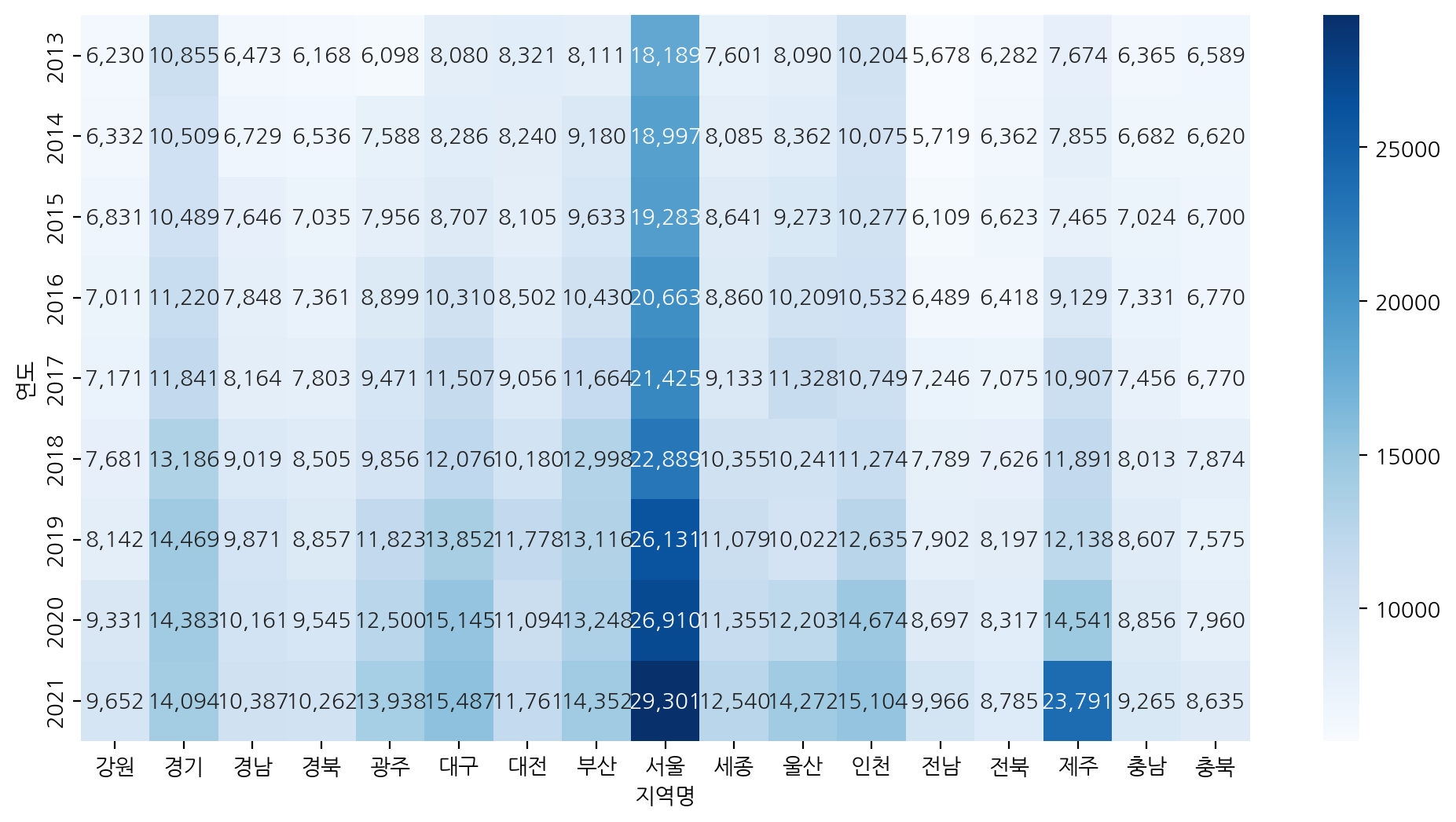
- Blues_r -> 색 스케일 반대로 작은 값을 더 진하게!
- annot = True -> 숫자 보이게
- fmt = ',.0f' -> 소수점 x, 천단위 ,
2013부터 최근 데이터까지 시각화
연도별 평당분양가격 보기
barplot으로 연도별 평당분양가격 그리기
plt.figure(figsize = (12, 4))
sns.barplot(data = df, x = '연도', y = '평당분양가격', errorbar = None).set_title('연도별 평균 평당 분양가격')
plt.figure(figsize = (12, 4))
sns.barplot(data = df, x = '연도', y = '평당분양가격').set_title('연도별 평균 평당 분양가격')
- errorbar 는 신뢰구간 -> 검은선 => 신뢰구간 표기하는데 계산이 오래걸려서 None으로 제외하고 사용
- 예전 버전은 ci
pointplot으로 연도별 평당분양가격 그리기
sns.pointplot(data = df, x = '연도', y = '평당분양가격', errorbar = None).set_title('연도별 평당 분양가격')
- pointplot()을 제외하고는 제목에 평균이 들어가는게 애매 why? 관측치는 평균이 맞고 bar, point는 그에 대한 평균을 다시 구해서 표기
-> 무슨…
boxplot으로 연도별 평당분양가격 그리기
sns.boxplot(data = df, x = '연도', y = '평당분양가격').set_title('평당 분양가격')
- bar, pointplot의 단점을 보완해서 만들어진 것이 boxplot
- bar, point는 대표값(평균, 합계 등)만을 표기 -> 대표값만으로는 데이터를 제대로 설명하기 어려움
- box=> 4분위수를 표기
- violin => 분포를 표기
- swarm => 관측값을 그대로 표기
violinplot으로 연도별 평당분양가격 그리기
sns.violinplot(data = df, x = '연도', y = '평당분양가격').set_title('평당 분양가격')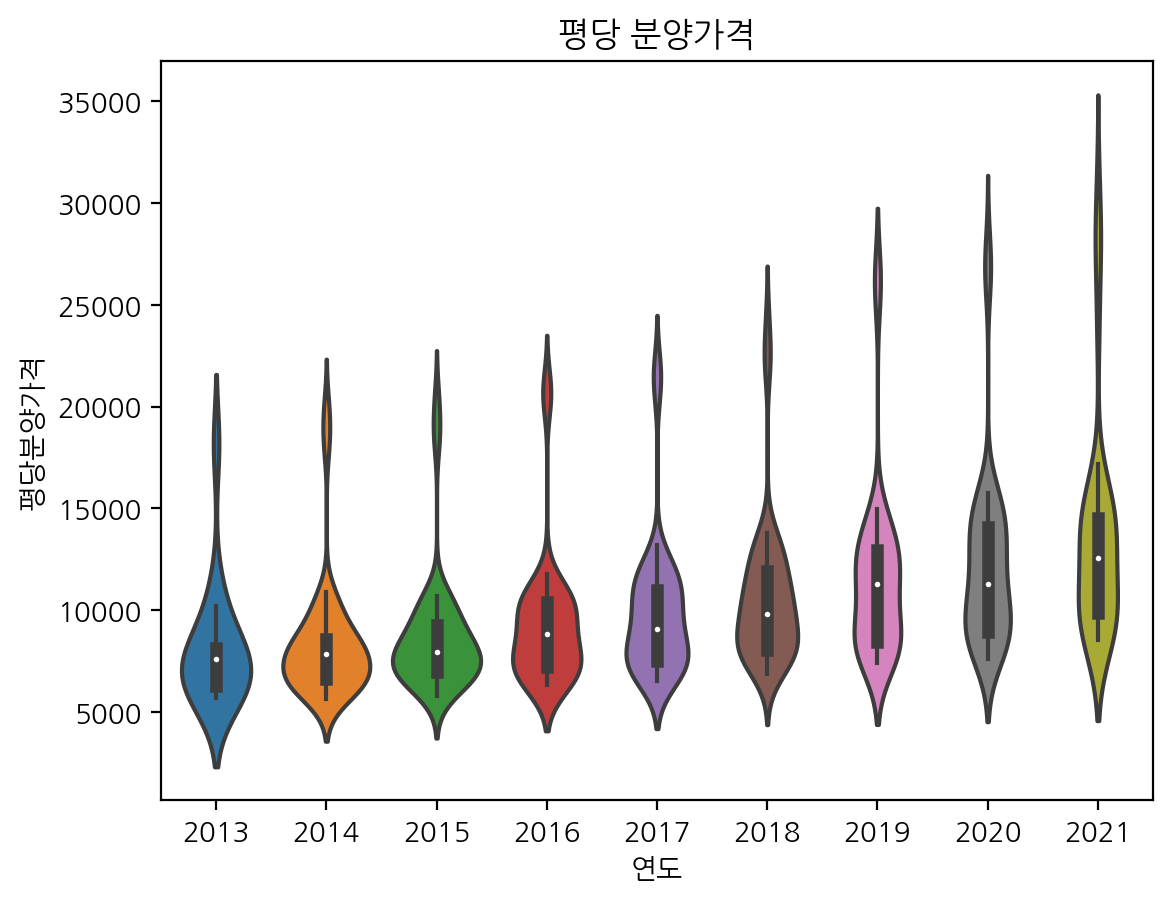
swarmplot으로 연도별 평당분양가격 그리기
plt.figure(figsize = (25, 12))
sns.swarmplot(data = df.reset_index(drop=True), x = '연도', y = '평당분양가격').set_title('연도별 평균 평당 분양가격') ;df.reset_index(drop=True) 하기(errorbar 업데이트 후에는 이걸 꼭 해야하는 것 같음)

sns.scatterplot(data = df, x = '연도', y = '평당분양가격').set_title('연도별 평균 평당 분양가격') ;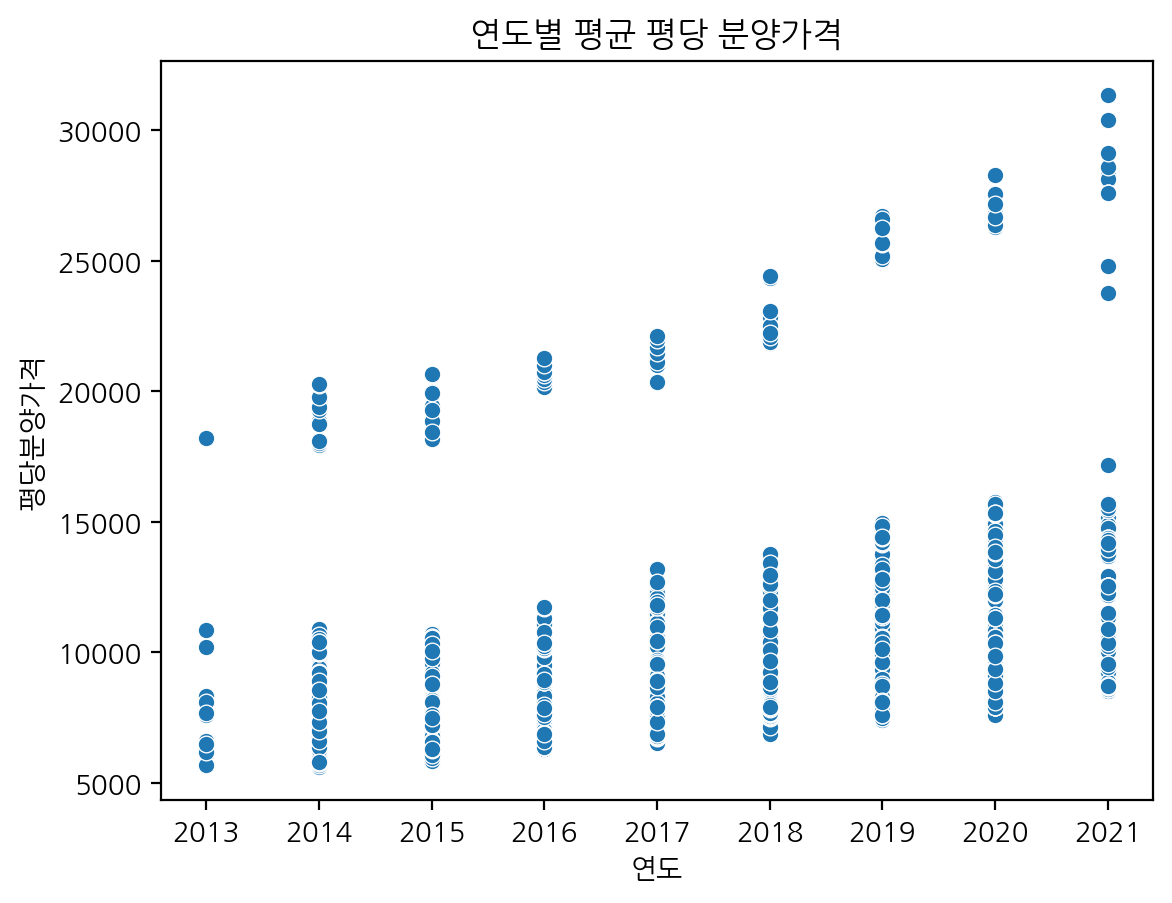
- scatterplot은 점이 겹침 -> 데이터가 얼마나 많고 적은지 알기 어려워서 옆으로 넓혀서 그리자! => swarmplot
지역별 평당분양가격
- 판다스 시각화의 장점은 계산기능을 제공하고 있지 않기 때문에 연산 후 시각화 해서 느리지 않음
- 판다스는 데이터프레임이나 시리즈에 바로 적용할 수 있는 장점
region_price = df.groupby('지역명')['평당분양가격'].mean().sort_values(ascending = False)
region_price.plot(kind = 'barh')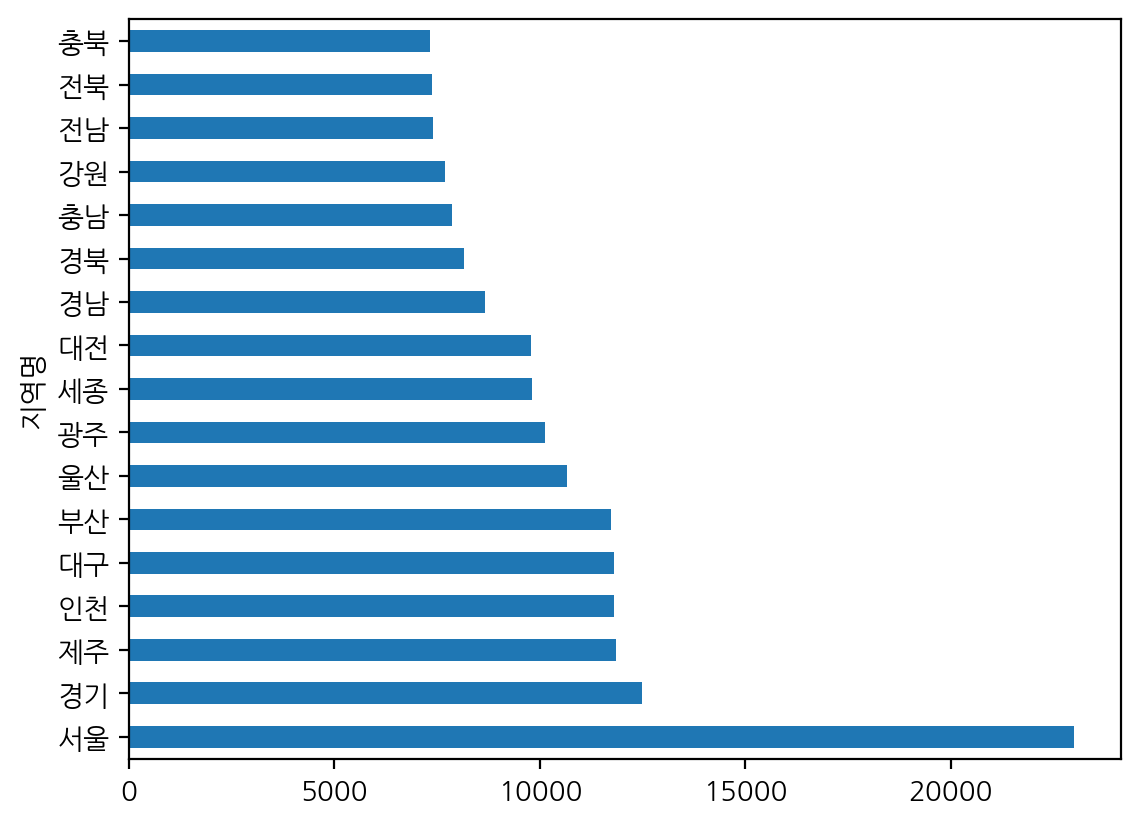
sns.barplot(data = df, x = '지역명', y = '평당분양가격',
order = region_price.index,
palette = 'Blues_r', errorbar = None).set_title('지역별 평당 분양가격')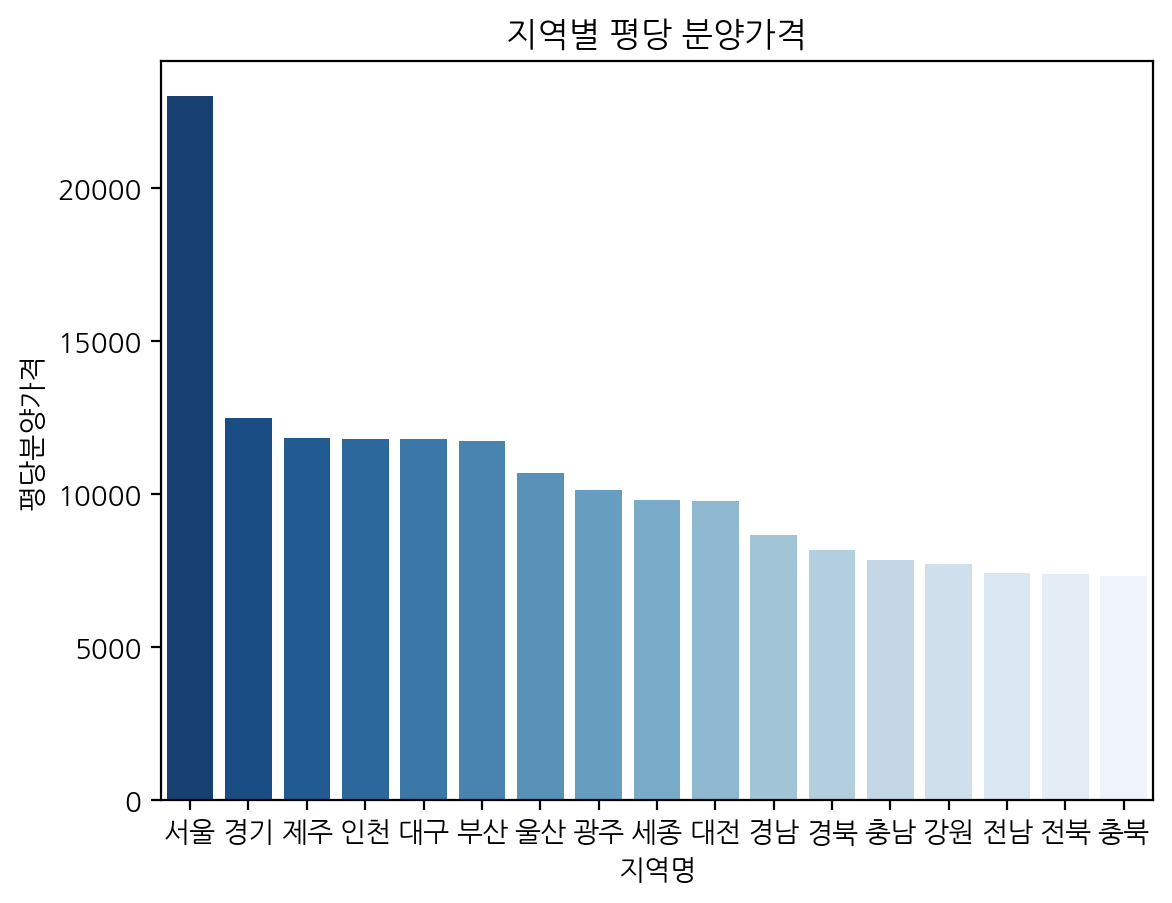
- 색은 최대한 적게(?) 쓰는 것이 좋음
- scale에 따라 정렬하는 것이 보기 좋음 -> 추천!
sns.boxplot(data = df, x = '지역명', y = '평당분양가격', order = region_price.index).set_title('지역별 평당 분양가격')
plt.figure(figsize = (12, 6))
sns.violinplot(data = df, x = '지역명', y = '평당분양가격', order = region_price.index).set_title('지역별 평당 분양가격')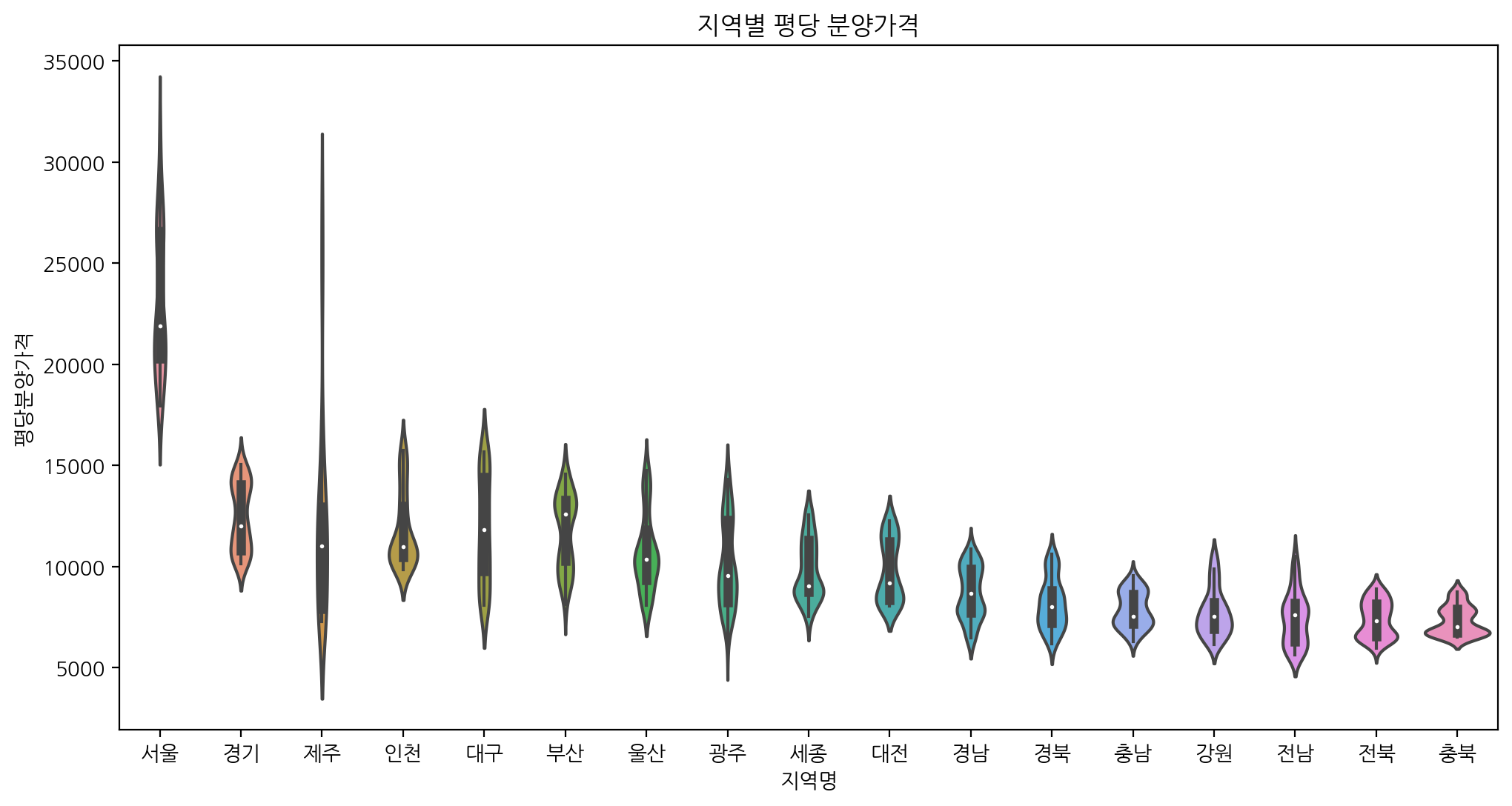
plt.figure(figsize = (40, 16))
sns.swarmplot(data = df.reset_index(drop = True), x = '지역명', y = '평당분양가격', order = region_price.index).set_title('지역별 평당 분양가격')
'AI SCHOOL > Python' 카테고리의 다른 글
| [Python] 비즈니스 데이터 분석(RFM) (0) | 2023.03.08 |
|---|---|
| [Python] 비즈니스 데이터 분석(Online Retail Data Set) (0) | 2023.03.07 |
| [Python] Plotly / FinanceDataReader (1) | 2023.02.02 |
| [Python] FinanceDataReader - 2 (0) | 2023.02.01 |
| [Python] FinanceDataReader - 1 (0) | 2023.01.31 |