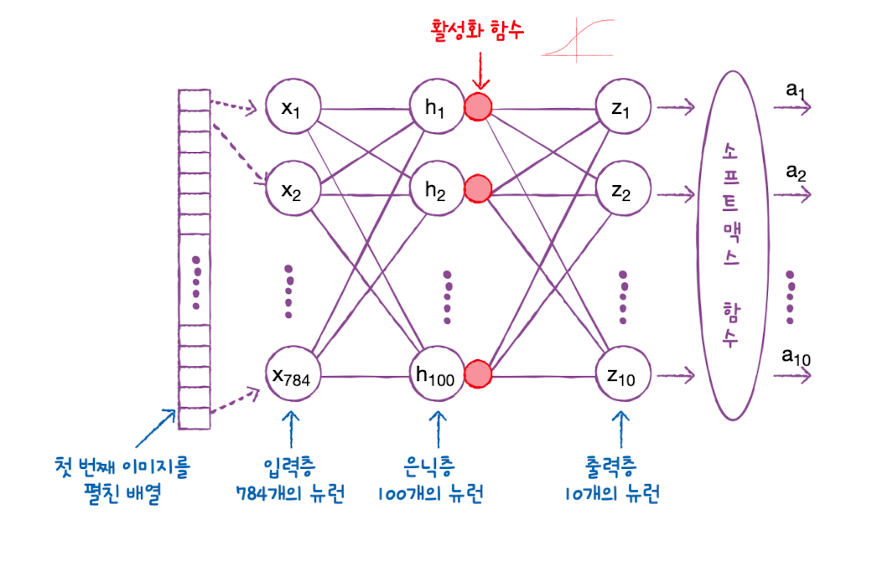
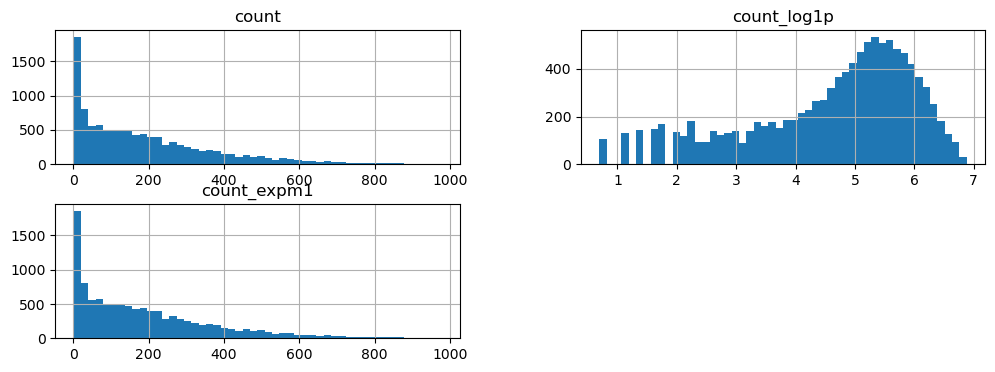
[Python] 코딩도장
1 - 2 1차원의 점들이 주어졌을 때, 그 중 가장 거리가 짧은 것의 쌍을 출력하는 함수를 작성하시오. (단 점들의 배열은 모두 정렬되어있다고 가정한다.) 예를들어 S={1, 3, 4, 8, 13, 17, 20} 이 주어졌다면, 결과값은 (3, 4)가 될 것이다. 문제 링크: https://codingdojang.com/scode/408 SS = [3, 4, 8, 13, 17, 20] 여도 (3, 4) 둘 사이 거리는 1 이니까 ! [답] s = [3, 4, 8, 13, 17, 20] m = float('inf') index = 0 for i in range(len(s) - 1): #1 if (m > s[i+1] - s[i]) : # 우리가 쓴 가장 큰 수보다 작으면 인덱스를 기억 #2 index = ..