- nunique 값이 2개인 칼럼은 binary encoding
- 그 외의 문자형 칼럼은 one hot encoding
- binary encoding
# nuni가 2인(변수가 두 개인) 피쳐 이름만 bicols라는 변수에 할당
nuni = df.drop(columns=label_name).nunique()
bicols = nuni[nuni == 2].index
# one hot encoding 하면 column이 더 생기니까 과적합 위험있음
# 그래서 boolean 으로 가능한건 한 column에서 해결
df["gender_bi"] = df["gender"] == "Male"
for yes_col in ['Partner', 'Dependents', 'PhoneService', 'PaperlessBilling']:
df[f"{yes_col}_bi"] = (df[yes_col] == "Yes").copy()
# True / False인 열 생김 -> 원래 칼럼은 지우거나 사용 x
df['gender_bi'] = df['gender'] == 'Male'- one hot encoding
# one-hot-encoding할 칼럼 추출
# binary encoding, 숫자 칼럼 제외
col_ohe = X_train.select_dtypes(include="object").drop(columns=['gender', 'Partner', 'Dependents', 'PhoneService',
'PaperlessBilling']).columns
# sklearn의 OneHotEncoder를 사용
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore')
X_train_ohe = ohe.fit_transform(X_train[col_ohe])
X_test_ohe = ohe.transform(X_test[col_ohe])
# X_train의 원핫인코딩 데이터 프레임 만들기
df_train_ohe = pd.DataFrame(X_train_ohe.toarray(), columns=ohe.get_feature_names_out())
# X_train 과 index(CustomerID) 똑같이 만들기
df_train_ohe.index = X_train.index
# X_train에서 숫자형과 논리형 데이터만 가져오기(바이너리, 원핫인코딩 안 한 object 제외)
X_train_num = X_train.select_dtypes(exclude="object")
# Ohe을 적용 안 한 데이터와 적용한 데이터를 병합
X_train_enc = X_train_num.join(df_train_ohe)- cross validation
# fit하기 전 train 데이터로 모델의 성능 점검
from sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train_enc, y_train,
cv=5, n_jobs=-1, verbose=1)
y_valid_predict[:5]
데이터셋 확인 및 전처리
데이터셋: Telco Customer Churn - https://www.kaggle.com/blastchar/telco-customer-churn / 고객 유지를 위한 행동 예측, 인구 통계 정보, 구독 서비스, 최근 한 달 이내에 탈퇴한 고객(Churn) 정보 등을 담고 있음
# 데이터 로드
df = pd.read_csv("https://bit.ly/telco-csv", index_col="customerID")
# 숫자형으로
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"], errors="coerce")
# 결측치 제거
df = df.dropna()
학습, 예측 데이터셋 나누기
# 정답값이자 예측해야 될 값
label_name = 'Churn'- binary encoding
- nunique값이 2개인 칼럼만 불러오기
- boolean값인 새로운 칼럼 만들기
nuni = df.drop(columns=label_name).nunique()
bicols = nuni[nuni == 2].index
df[bicols].head(2)
df = df.copy()
df["gender_bi"] = df["gender"] == "Male"
for yes_col in ['Partner', 'Dependents', 'PhoneService', 'PaperlessBilling']:
df[f"{yes_col}_bi"] = (df[yes_col] == "Yes").copy()
df.head(2)
# 반복문 안 쓴다면
df['Partner_bi'] = df['Partner'] == 'Yes'
df['Dependents_bi'] = df['Dependents'] == 'Yes'
df['PhoneService_bi'] = df['PhoneService'] == 'Yes'
df['PaperlessBilling_bi'] = df['PaperlessBilling'] == 'Yes'
- 학습, 예측 데이터셋 만들기
# 문제(feature)와 답안(label) 나누기
X_raw = df.drop(columns=label_name)
y = df[label_name]# 학습, 예측 데이터셋
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_raw, y, test_size=0.2, stratify=y, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
- One-hot-Encoding
- 원핫인코딩 할 변수 골라내기
- 인코딩 필요한 object 데이터 가져오고 binary encoding 한 변수 제외
col_ohe = X_train.select_dtypes(include="object").drop(columns=['gender', 'Partner',
'Dependents', 'PhoneService',
'PaperlessBilling']).columns
- 머신러닝 알고리즘은 문자 데이터 사용 X
- sklearn에서 인코딩 하면 데이터프레임으로 변환해주지 않고 numpy array 형태라 Data Frame으로 만들어줘야 함
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore')
X_train_ohe = ohe.fit_transform(X_train[col_ohe])
X_test_ohe = ohe.transform(X_test[col_ohe])-> train 은 fit_transform(), test는 transform()
-> handle_unknown='ignore'을 설정하여 검증 데이터에서 학습데이터에서는 존재하지 않는 class들을 만났을 때 발생하는 오류를 방지
# ohe 한 피처의 이름
ohe.get_feature_names_out()
# numpy array 형태
X_train_ohe.toarray()
df_train_ohe = pd.DataFrame(X_train_ohe.toarray(),
columns=ohe.get_feature_names_out())
df_train_ohe.index = X_train.index
df_train_ohe.head(2)
# train 데이터에서 수치형 데이터만 가져오기
X_train_num = X_train.select_dtypes(exclude="object")
# X_train_num(수치형 데이터)와 ohe해서 DataFrame만들어 준 데이터 합치기
X_train_enc = pd.concat([X_train_num, df_train_ohe], axis=1)
X_train_enc.head()
# 테스트 데이터도 똑같게
df_test_ohe = pd.DataFrame(X_test_ohe.toarray(), columns=ohe.get_feature_names_out())
df_test_ohe.index = X_test.index
X_test_num = X_test.select_dtypes(exclude="object")
X_test_enc = pd.concat([X_test_num, df_test_ohe], axis=1)
ExtraTreesClassifier
- 분류를 위한 앙상블 학습 알고리즘 중 하나 -> 무작위 결정 트리 사용
- Random Forest와 유사하지만 각 노드에서 특징(feature)의 무작위 임계값(random threshold)을 사용하여 더욱 무작위한 결정 트리를 생성 -> 모델의 분산 줄이고, 과적합 방지
- ExtraTreesClassifier는 데이터가 매우 크거나 복잡한 경우에 유용하며, 다른 분류 알고리즘과 비교하여 더 빠른 속도로 학습 -> 데이터 상대적으로 작은 경우 다른 모델과 성능 비슷하거나 떨어질 수도
- 주요 파라미터
- n_estimators : int, default=100
: 숲에 있는 나무의 수
- criterion : criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
: 분할의 품질을 측정하는 피처
- max_depth : int, default=None
: 트리의 최대 깊이
- min_samples_split : int or float, default=2
: 내부 노드를 분할하는 데 필요한 최소 샘플 수
- max_features : {“sqrt”, “log2”, None}, int or float, default=”sqrt”
: 최상의 분할을 찾을 때 고려해야 할 피처의 수
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier(random_state=42)
model
Cross Validation(교차검증)
- 어떤 모델이 좋은 성능을 내는지 평가 할 때 사용
- 데이터셋을 여러 번 반복적으로 나누어 학습 및 검증을 수행하고, 각각의 결과를 평균화하여 일반화 성능을 측정
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_predict.html
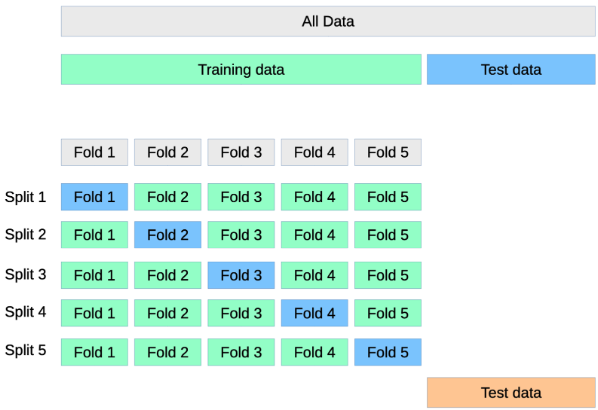
- 교차검증 함수
- cross_val_predict : 예측 결과만 반환, 점수를 직접 계산 => 다양한 측정 공식으로 점수 측정이 가능
- cross_val_score : 지정한 metric으로 예측 점수를 반환
- cross_validate : 지정한 metric으로 예측 점수와 시간을 반환
- cross_val_predict의 파라미터
- cv: 교차검증을 수행 할 폴드(fold)의 수 -> 이 값이 크면 교차검증의 정확도는 증가하지만, 모델 학습 및 검증에 걸리는 시간은 증가(기본값은 5)
- mothod: 예측값을 구하는 방법, 기본값은 'predict' -> 'method'파라미터에 'predict_proba'입력하면 모델이 각 클래스에 속할 확률을 반환
- n_jobs: 교차검증을 수행할 때 사용되는 CPU 코어의 개수를 지정(기본값은 1) -> -1로 지정하면 모든 CPU 코어를 사용
'n_jobs'를 늘리면 교차검증을 더 빠르게 수행할 수 있지만, 사용하는 CPU 코어가 많아질수록 메모리 사용량도 증가 - verbose: 교차검증 수행 시 로그 메시지를 출력하는 빈도를 조절
from sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train_enc, y_train,
cv=5, n_jobs=-1, verbose=1)
y_valid_predict[:5]
# fit
model.fit(X_train_enc, y_train)
# predict
y_predict = model.predict(X_test_enc)
# 정확도(accuracy)는 성능 평가 기준 중 하나로, 전체 샘플 중에서 올바르게 예측한 샘플 수를 의미
(y_test == y_predict).mean()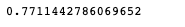
모델 평가
# feature_importances_
fi = pd.Series(model.feature_importances_)
fi.index = model.feature_names_in_
fi.nlargest(10).plot.barh()
'AI SCHOOL' 카테고리의 다른 글
| [ML] GridSearch / GradientBoostingRegressor (0) | 2023.03.19 |
|---|---|
| [ML] ExtraTreesRegressor / 회귀 모델 평가 지표(MAE, MSE, RMSE, r2_Score) (0) | 2023.03.18 |
| [ML] one-hot encoding / Random Forest (0) | 2023.03.18 |
| [ML] Decision Tree (0) | 2023.03.17 |
| [ML] Clustering (0) | 2023.03.12 |