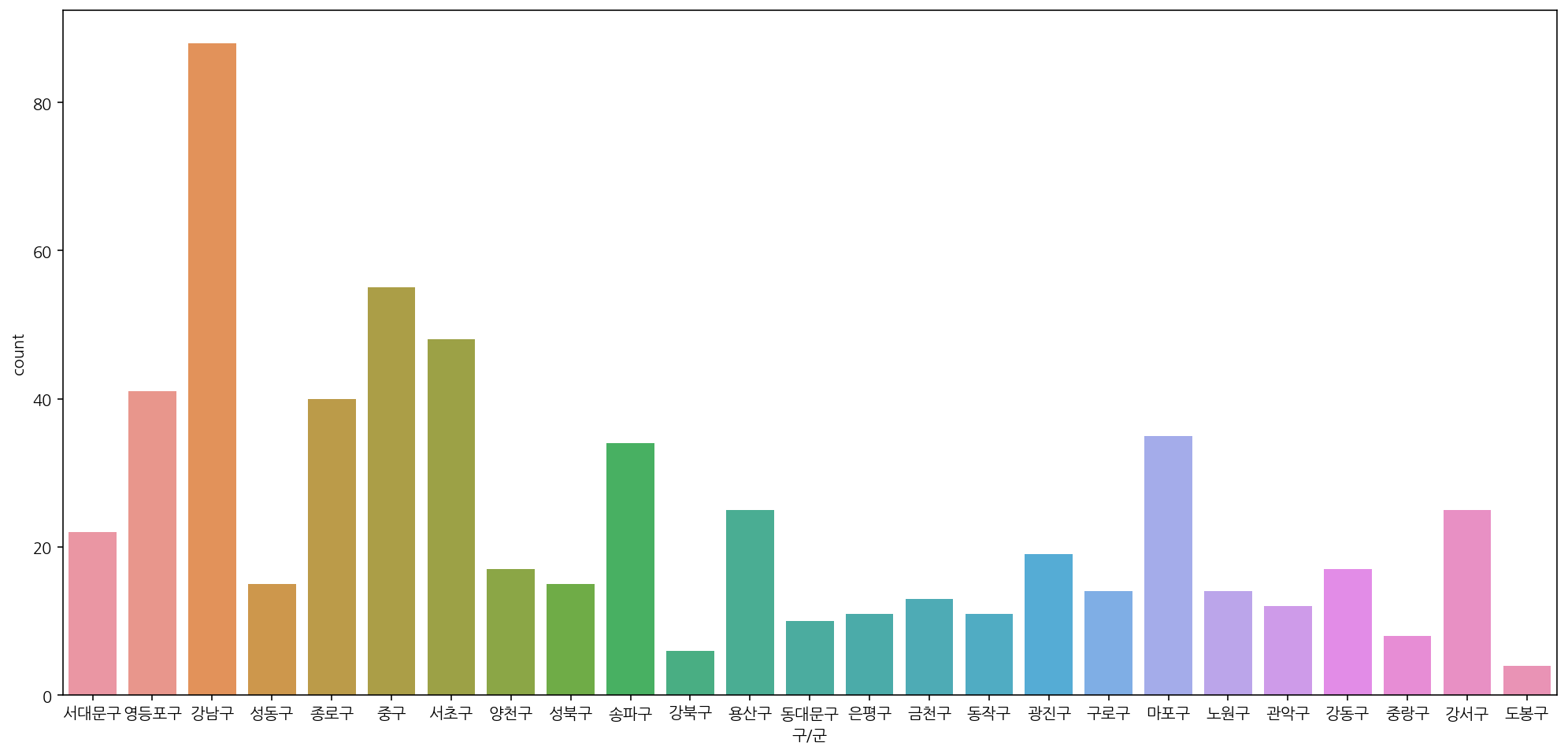
사용한 데이터 라이브러리 및 데이터 불러오기 import pandas as pd import numpy as np import matplotlib.pyplot as plt import plotly import plotly.express as px import koreanize_matplotlib df_sectors = pd.read_csv('전체_재해_현황_및_분석업종별_산업별_중분류__20230202111602.csv', encoding = 'cp949') df_age = pd.read_csv('전체_재해_현황_및_분석연령별_산업별_중분류_21년', encoding = 'cp949') df_dt = pd.read_csv('118_DT_11806_..