타시도, 기타 전처리
# 공백 없애기
df['거주구'] = df['거주지'].str.strip()
# 타시도 -> 기타
df['거주구'] = df['거주구'].str.replace('타시도', '기타')
# 거주구 빈도수 구하기
gu_count = df['거주구'].value_counts()gu_count 변수에 담긴 값 시각화 하기
- 선 그래프: 연속된 데이터 시각화
- 막대 그래프: 범주형(끊어져 있는) 데이터 시각화
# r => red, b=> blue, k => black
# h => horizontal 가로
# v => vertical 세로
gu_count.plot.bar()
plt.axhline(5000, c="r", ls=":")
plt.axvline(5, c="y", ls=":")
두 개의 변수에 대한 빈도수 구하기
연도, 퇴원현황 두 개의 변수에 대한 빈도수 구하기
pd.crosstab(index=df['연도'], columns = df['퇴원현황'])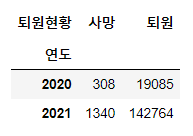
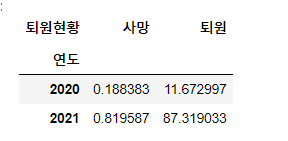
두 변수에 대한 빈도 비율 구하기
pd.crosstab(index=df['연도'], columns = df['퇴원현황'], normalize = True)
* 100 을 하면
연도, 월 두 개의 변수에 대한 빈도수 구하기
- pd.crosstab 으로 연도, 월 두 개의 변수에 대한 빈도수 구하기
pd.crosstab(index=df['연도'], columns = df['월'])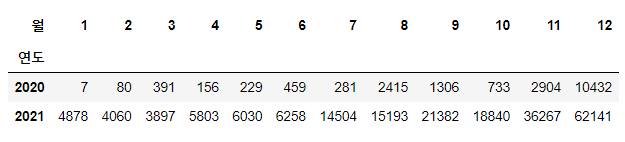
pd.crosstab(index=df['연도'], columns = df['월'], normalize = True)
cross_2 = pd.crosstab(index=df['연도'], columns = df['월'])
cross_2.plot.bar(rot = 0, figsize = (12, 3))

-> 색이 너무 많음, 한눈에 알아보기 힘듦
cross_2.T.plot.bar(rot = 0, figsize = (12, 3)) ;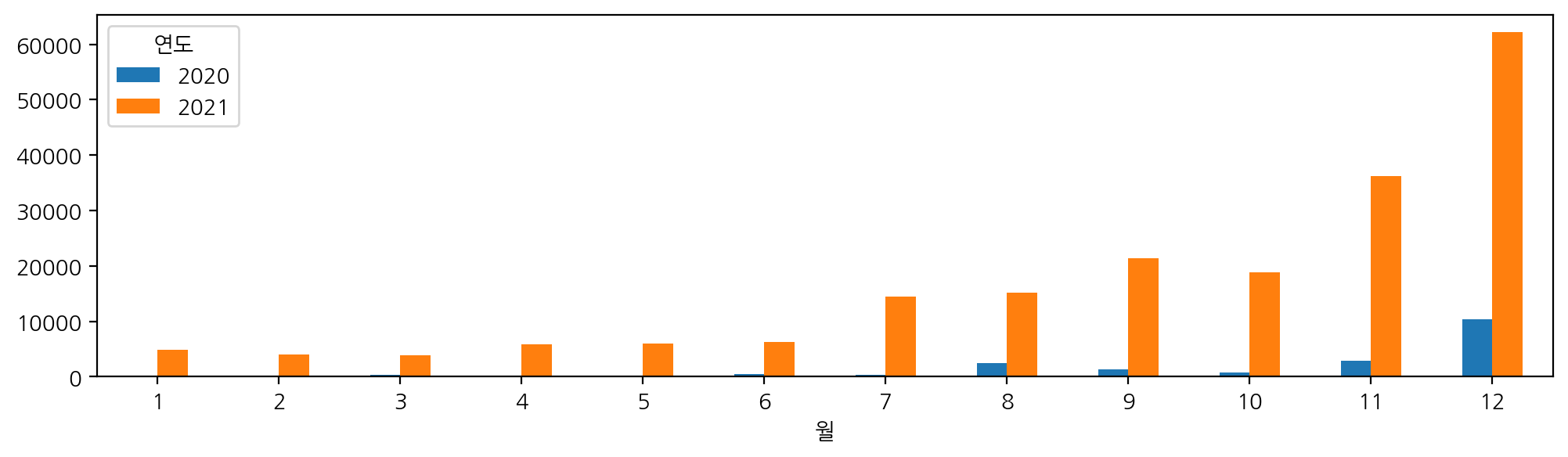
연도, 요일 두 개의 변수에 대한 빈도수 구하기
pd.crosstab(index=df['연도'], columns = df['요일'], normalize = True) * 100
cross_1 = pd.crosstab(index=df['연도'], columns = df['요일'])
cross_1.T.plot.bar(rot = 0, figsize = (12, 3)) ;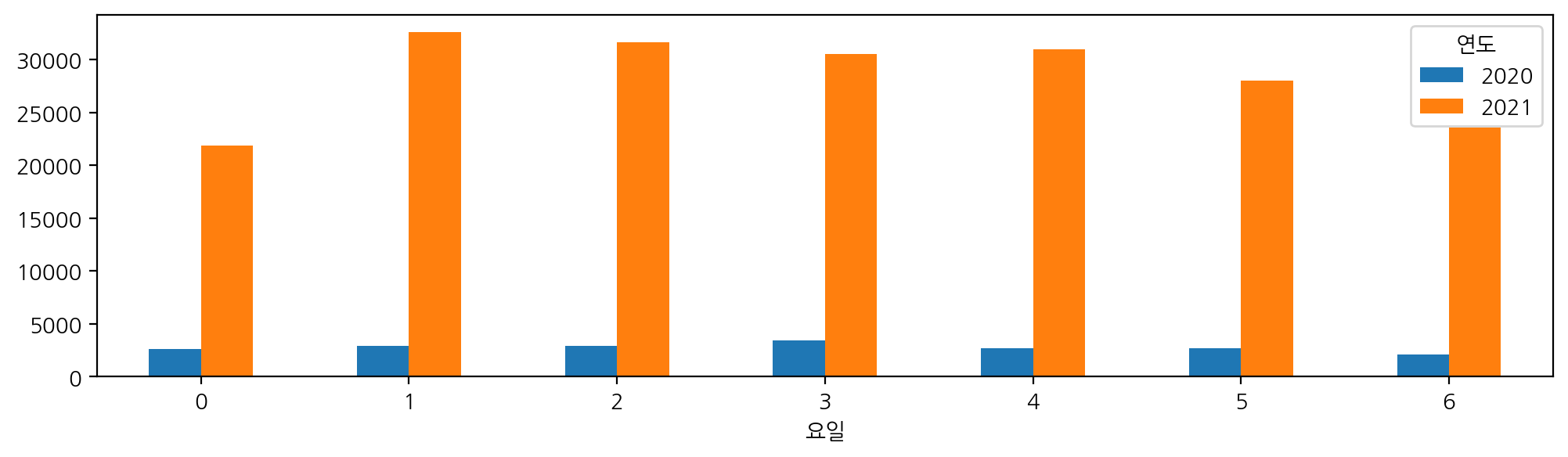
그런데 연도, 요일 crosstab 한 부분에서 각 열 별로 합계가 100이 되게 만들 수는 없을까?
-> 직접 계산 하는 것을 추천 (근데 왜?)
cross_1t = cross_1.T
cross_1t['합계'] = cross_1t.sum(axis = 1)
cross_1t['합계']
cross_1t['2021/2020'] = cross_1t[2021] / cross_1t[2020]
cross_1t
그 외에도

월화수목금토일
yoil_y = pd.crosstab(index=df['연도'], columns = df['요일'], normalize = 'index')*100
weekday_list = [i for i in '월화수목금토일']
weekday_list
>> ['월', '화', '수', '목', '금', '토', '일']# 컬럼명 변경하기
yoil_y.columns = weekday_list
yoil_y.T.plot.bar(rot = '0', figsize = (6, 3))
거주구, 연도월에 대한 빈도수 구하기
gu_ym = pd.crosstab(df['거주구'], df['연도월'])background_gradient()로 빈도수 표현하기 -> 해당 칼럼의 숫자를 비교해서 색상을 표시
gu_ym.style.background_gradient()
gu_ym.T.style.background_gradient()
Boolean Indexing으로 특정 조건 값 찾기
여러 조건 비교하기
gu_ym.iloc[:5, -5:]
강남구에서 '일요일'에서 확진된 사람의 거주구 요일명 데이터만 찾기
df.loc[(df['거주구'] == '강남구') & (df['요일명'] == '일'), ['거주구', '요일명']]
거주구가 강남구이며, 여행력이 일본인 데이터 찾기
df.loc[(df['거주구'] == '강남구') & (df['여행력'] == '일본')]
# .loc[행]
# .loc[행, 열]
# .loc[조건, 열]
str.contains 활용하기
df[df['접촉력'].str.contains('pc')]
이렇게 하면 소문자만 나옴 -> 그래서 다 대문자로 바꾸고 찾기
df['접촉력_대문자'] = df['접촉력'].str.upper()
df.loc[df['접촉력_대문자'].str.contains('PC'), '접촉력'].value_counts()
isin 으로 여러 값 찾기
isin을 사용해서 리스트로 여러값 찾아오기
'거주구'가 '강남구', '서초구', '송파구'인 데이터만 찾기
df.loc[df['거주구'].isin(['강남구', '서초구', '송파구']), '접촉력'].value_counts()
str.contains()로 "거주구"가 "강남구", "서초구", "송파구" 인 데이터만 찾기
df.loc[df['거주구'].str.contains("강남구|서초구|송파구"), '거주구'].value_counts()
# and나 or로 하면 제대로 가져오지 못함

isin : 완벽히 일치하는 것, 데이터프레임에서도 사용 가능
.str. : 일부만 일치해도 o, 시리즈에만 사용 가능 -> 특정 데이터 타입에서만 str제공하기 떄문 (문자열 accessor 라서)
https://pandas.pydata.org/docs/reference/series.html#string-handling
Series — pandas 1.5.3 documentation
Warning Series.attrs is considered experimental and may change without warning.
pandas.pydata.org
여행력
df['해외유입'] = df['접촉력'] == '해외유입'
df.head(3)
df['해외유입'].value_counts(1) * 100
df.loc[df['해외유입'], '국내해외'] = '해외'
df.loc[~ df['해외유입'], '국내해외'] = '국내'
df.head()해외유입에 true 이면 '국내해외' 칼럼에 해외를 넣고, false 면 '국내'를 넣는다
거주구별 해외유입 비율 구하기
pd.crosstab(index = df['거주구'], columns = df['국내해외'], normalize = True) * 100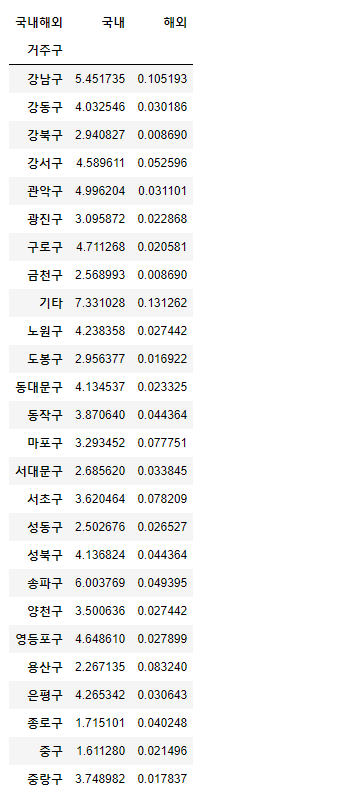
해외 유입 여부에 따라 막대 그래프 그리기 stacked = True
abroad = pd.crosstab(index = df['거주구'], columns = df['국내해외'], normalize = True) * 100
abroad.plot(kind = 'bar', stacked = True, rot = 80) ;
abroad.plot(kind = 'bar', subplots = True) ;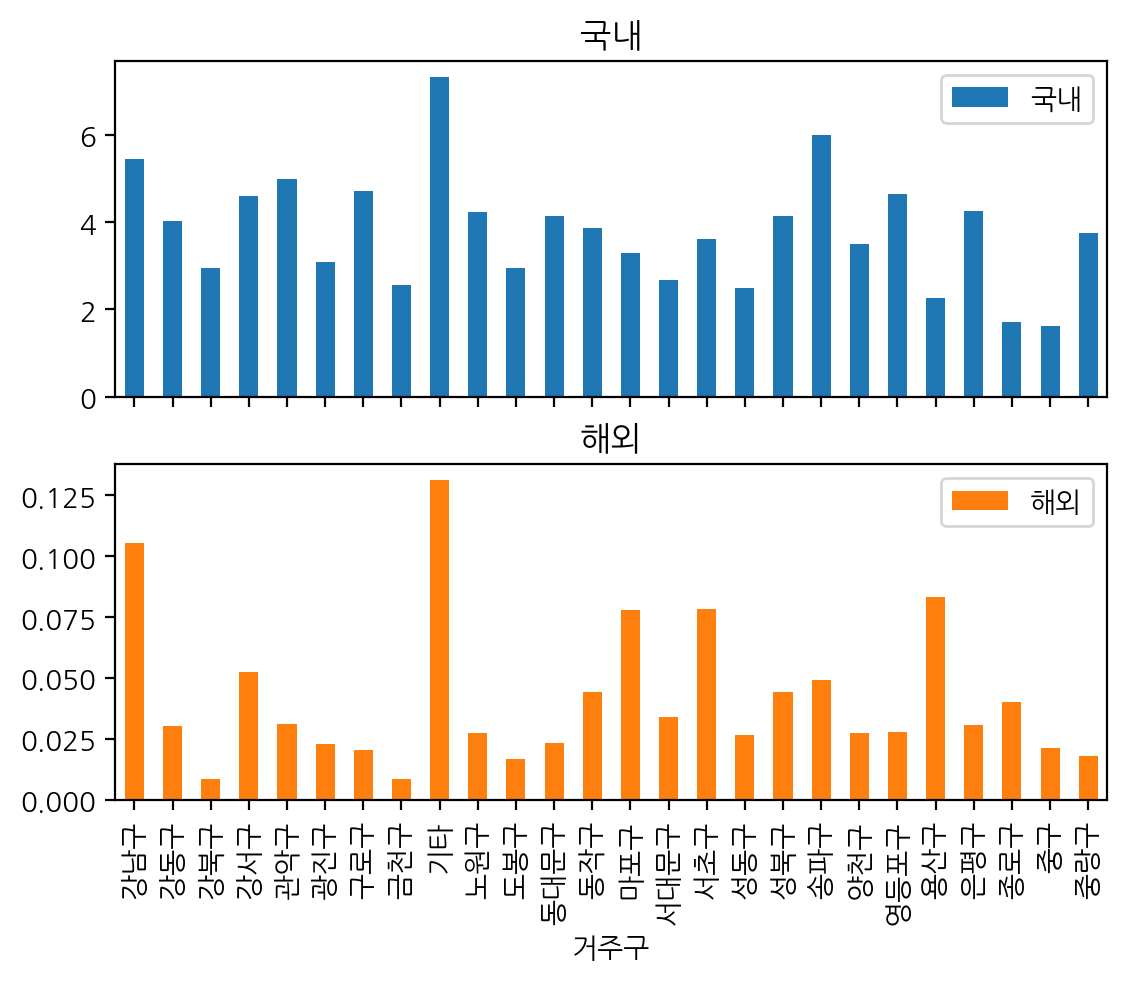
해외비율 칼럼 만들어서
- 거주구 해외유입 비율구하기
- 기준에 따라 전체 확진수에 대한 비율 구할 수 있고 국내, 해외 비율 구할 수도 있고 여러 기준으로 구할 수 있을 텐데, 기준을 명시해주면 해석에 용이
gu_oversea = pd.crosstab(df['거주구'], df['국내해외'])
gu_overseagu_oversea = pd.crosstab(df['거주구'], df['국내해외'])
gu_oversea['해외비율'] = gu_oversea['해외'] / gu_oversea['국내']
gu_oversea
gu_oversea[['국내', '해외']].sort_values('국내').plot(kind = 'barh', stacked = True)
- barh : bar와 다르게 가로 막대그래프
- sort_values('국내')
- 막대 그래프 -> 범주형 데이터
- 선 그래프 -> 연속된 수치 데이터에서 주로 사용
pivot_table 사용

- pd.crosstab()의 소스코드를 보게 되면 내부가 pd.pivot_table() 로 되어있음
- pd.crosstab() 은 pivot_table()을 사용하기 쉽게 한번 더 감싸(wrapping) 놓은 기능
- pd.crosstab() 에 비해 pivot_table() 을 사용하면 좀 더 많은 기능을 사용할 수 있음
- pivot, pivot_table 공통점 index, columns, values 를 공통적으로 사용
- pivot 은 형태 변환만 제공하고 / pivot_table 은 연산을 함께 제공합니다. pivot_table 은 aggfunc 등의 기능을 제공 groupby() 를 사용하기 쉽게 엑셀에서 사용하는 용어로 만들어 놓은 것이 pivot_table() 입니다.
pd.pivot_table(data = df, index= '거주구',
columns= '국내해외',
values = '환자',
aggfunc= 'count')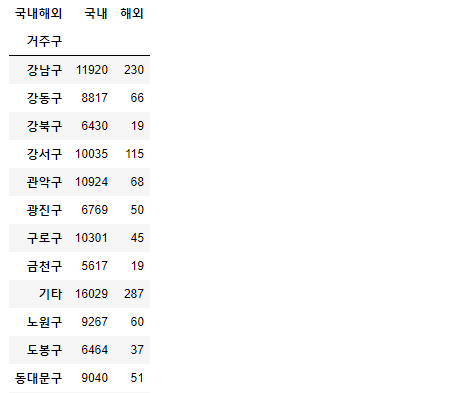

-> values에 어떤 칼럼을 넣는거지? 유니크하고 결측치도 없는 것으로 지정, 중복값이 있더라도 nunique()가 아니고 count()를 사용하면 빈도를 구함 => 무슨말이징ㅅ
거주구에 따른 요일별 확진자 빈도수
df_gu_weekday = pd.pivot_table(data = df, index= '거주구',
columns = '요일',
values = '환자',
aggfunc= 'count')
df_gu_weekday.columns = weekday_list
df_gu_weekday.style.bar()
groupby 사용하기
df2 = pd.DataFrame({'Animal': ['Falcon', 'Falcon',
'Parrot', 'Parrot'],
'Max Speed': [380., 370., 24., 26.]})
df2.groupby(['Animal']).mean()

'거주구', '국내해외'로 그룹화 하여 '환자' 칼럼으로 빈도수 구하기
df.groupby(by = ['거주구', '국내해외'])['환자'].count()
groupby의 unstack()
- "거주구", "국내해외" 으로 그룹화 하여 "환자" 컬럼으로 빈도수 구하고 마지막 인덱스를 컬럼으로 만들기
gu_os = df.groupby(by = ['거주구', '국내해외'])['환자'].count()
gu_os.unstack()
- 연도, 월을 멀티인덱스로 사용하는 빈도수 구하기
df.groupby(['연도', '월'])['국내해외'].describe()
'AI SCHOOL > Python' 카테고리의 다른 글
| [Python] FinanceDataReader - 2 (0) | 2023.02.01 |
|---|---|
| [Python] FinanceDataReader - 1 (0) | 2023.01.31 |
| [Python] 서울 코로나 데이터 분석(EDA) - 1 (0) | 2023.01.30 |
| [Python] Open API 사용하여 서울시 다산 콜센터 자주 묻는 질문 목록 데이터 수집 (0) | 2023.01.24 |
| [Python] 네이버 금융 ETF 수집, json 데이터 수집 (0) | 2023.01.24 |