- 비즈니스 데이터 분석
- 서비스의 특징에 따라 봐야하는 지표가 다르다.
- 회원가입에 집중? 돈을 쓰는 고객에 집중? 신규 고객 유치에 집중?
- 광고, 프로모션, 오프라인 행사 등 여러가지 마케팅을 실시 구독 서비스라면 이탈률이 중요한 지표
- ARPU(Average Revenue Per User, 앱 활동 사용자의 1인당 평균 결제 금액 = 매출 / 중복을 제외한 순수 활동 사용자 수)
- ARPPU(Average Revenue Per Paying User, 유료 사용자 1인당 평균 결제 금액 = 매출 / 중복을 제외한 순수 유료 사용자 수)
- MRR
- ARR
https://easytoread.tistory.com/entry/CAC-CPA-%EC%B0%A8%EC%9D%B4
【마케팅】 CAC, CPA, CPL 의미와 차이점 + LTV와의 관계
마케팅의 효율을 측정하는 것은 매우 중요합니다. 광고비(본전) 보다 많이 버는 것이 마케팅의 목적이니까요. 효율을 측정하는 것이 쉽지만은 않지만 CAC, CPA, CPL 그리고 LTV를 활용한다면 비교적
easytoread.tistory.com
Q. 소매, 리테일 서비스에 머신러닝을 어떻게 활용할 수 있을까요?
고객 분석
- 고객 데이터를 수집하고 분석하여 구매 패턴, 구매 선호도, 구매력 등을 파악합니다.
- 머신러닝을 활용하여 고객 데이터를 분석하면 고객의 취향과 관심사에 대한 인사이트를 얻을 수 있으며, 이를 기반으로 개별 고객에게 맞춤형 서비스를 제공할 수 있습니다.
재고 관리
- 머신러닝을 활용하여 소매업체는 과거 판매 이력, 계절성 및 트렌드 등을 고려하여 재고를 관리합니다.
- 머신러닝 모델은 판매 이력을 분석하고, 트렌드를 파악하여 재고 수준을 최적화하고 재고 부족 현상을 예측합니다.
가격 설정
- 머신러닝을 활용하여 경쟁 업체의 가격 변화를 모니터링하고, 이를 기반으로 자동으로 가격을 조정한다.
추천 시스템
- 머신러닝을 활용하여 추천 시스템을 구축할 수 있습니다.
- 고객 구매 이력과 관련 상품, 구매 내역, 구매 인기도 등을 고려하여 개별 고객에게 맞춤형 상품을 추천할 수 있습니다. -> 고객 만족도와 매출 증대에 기여
사기 탐지
- 머신러닝을 활용하여 이상 거래를 탐지할 수 있습니다.
- 머신러닝 모델은 고객 구매 이력과 관련 데이터를 분석하여 이상 거래를 탐지하고, 대응 조치를 취할 수 있습니다
- AARRR
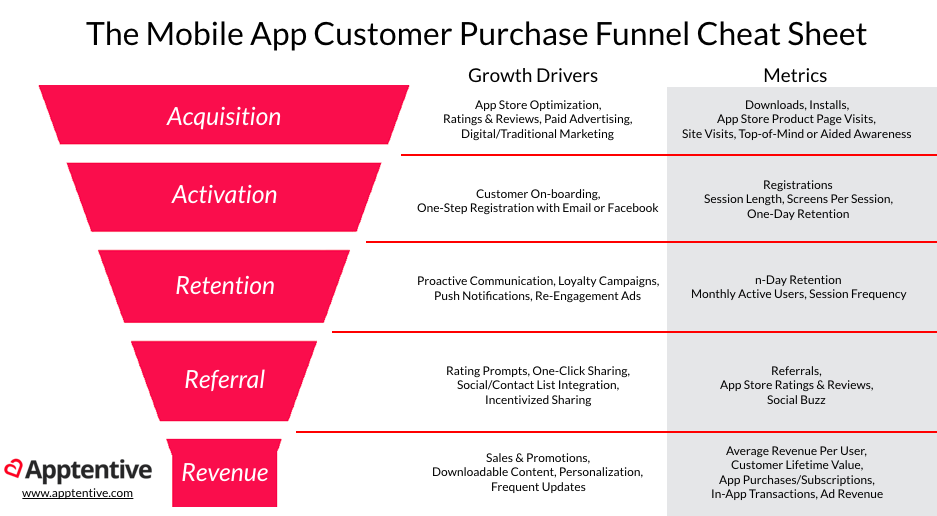
- 시장 진입 단계에 맞는 특정 지표를 기준으로 우리 서비스의 상태를 가늠할 수 있는 효율적인 기준
- 현 시점에서 가장 핵심적인 지표에 집중할 수 있게 함
- 고객 유치(Acquisition), 활성화(Activation), 리텐션(Retention), 수익화(Revenue), 추천(Referral)
- 코호트 분석
- 앱 가입 날짜, 첫 구매 월, 위치, 획득 채널(유기 사용자, 공연 마케팅에서 오는 것 등) 등과 같은 공통점을 공유하는 사람들의 그룹을 시간 경과에 따라 추적하여 몇 가지 일반적인 패턴 또는 행동을 식별하는 분석 방법
- 시간의 흐름을 기준으로 고객 세분화
- 시간 집단 / 행동 집단 / 규모 집단
- 시간 집단 : 특정 기간동안 제품이나 서비스에 가입한 고객
- 행동 집단 : 과거에 제품을 구매했거나 서비스에 가입한 고객
- 규모집단 : 회사 제품이나 서비스를 구매하는 다양한 규모의 고객
라이브러리 로드 및 폰트 설정
import pandas as pd
import numpy as np
import seaborn as sns
import datetime as dt
import matplotlib.pyplot as plt
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'
데이터 불러오기 및 미리보기
df = pd.read_csv('data/online_retail.csv')
df.shape
>> (541909, 8)- 데이터셋: https://archive.ics.uci.edu/ml/datasets/Online+Retail#
- excel 파일로 데이터를 불러올 때는 용량이 크면 로드하는데 1분 이상이 걸릴 수 있음
- 같은 파일이라면 csv가 빠름
df.head(5)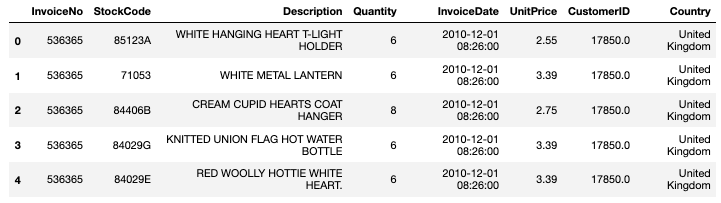
df.info()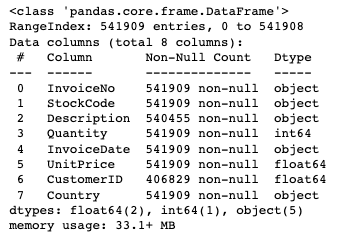
Attribute Information:
InvoiceNo: Invoice number. Nominal, a 6-digit integral number uniquely assigned to each transaction. If this code starts with letter 'c', it indicates a cancellation.(이 코드가 문자 'c'로 시작하면 취소를 나타냄)
StockCode: Product (item) code. Nominal, a 5-digit integral number uniquely assigned to each distinct product.
Description: Product (item) name. Nominal.
Quantity: The quantities of each product (item) per transaction. Numeric. (이 코드가 ‘-’(마이너스)로 시작하면 취소를 나타냄)
InvoiceDate: Invice Date and time. Numeric, the day and time when each transaction was generated.
UnitPrice: Unit price. Numeric, Product price per unit in sterling.
CustomerID: Customer number. Nominal, a 5-digit integral number uniquely assigned to each customer.
Country: Country name. Nominal, the name of the country where each customer resides.
기술통계
df.describe()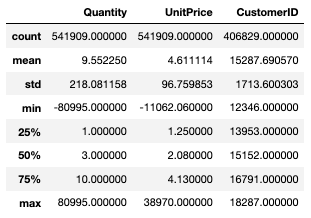
df.describe(include = 'O')
InvoiceNo로 알 수 있는 것은?
: 573585 품목이 제일 많이 구매 및 취소를 했고, 1114개의 아이템 종류가 있다
가장 많은 InvoiceNo의 개수가 573585이고, 해당 주문의 StockCode의 종류가 1114개
예를 들어, 한번 주문을 할 때, 콩나물, 두부, 생선, 커피 등을 주문했는데 이 종류가 1114개
전체 주문은 54만건이지만 유니크한 주문건은 2.5만개(= 중복을 뺀 것이 25900개 제일 많이 중복 된 애의 NO는 573585, 중복 된 애의 최대 수 1114)
# 결측치 합계
df.isnull().sum()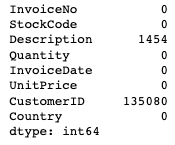
- CustomerID 0.249267 의 결측치는 비회원 구매일 수 있음
- 실제 업무에서는 담당자에게 물어보고 확실히
# 결측치 비율
# df.isnull().sum()/len(df) 밑처럼 하는 게 깔끔함
df.isnull().mean()
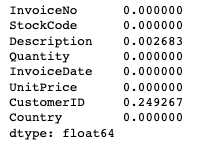
# 결측치를 시각화
plt.figure(figsize=(12, 4))
sns.heatmap(df.isnull())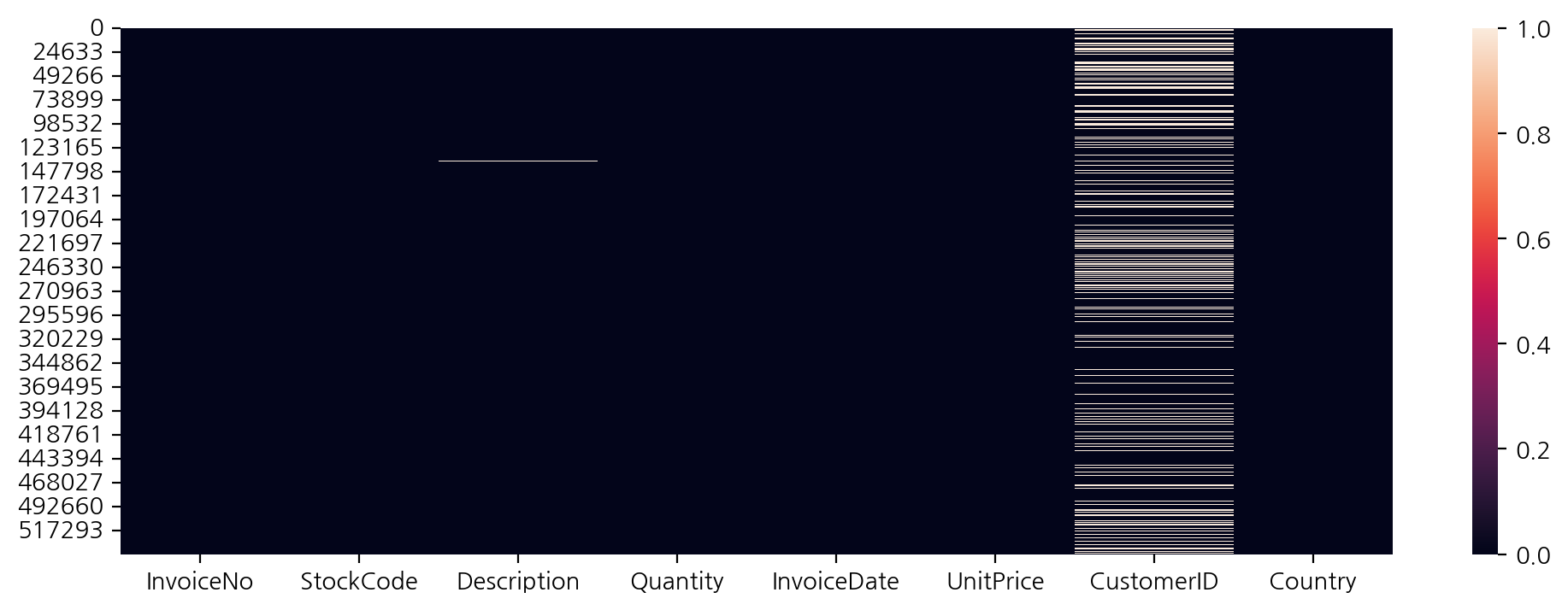
히스토그램으로 전체 수치변수 시각화
df.hist(bins = 50, figsize = (12, 6));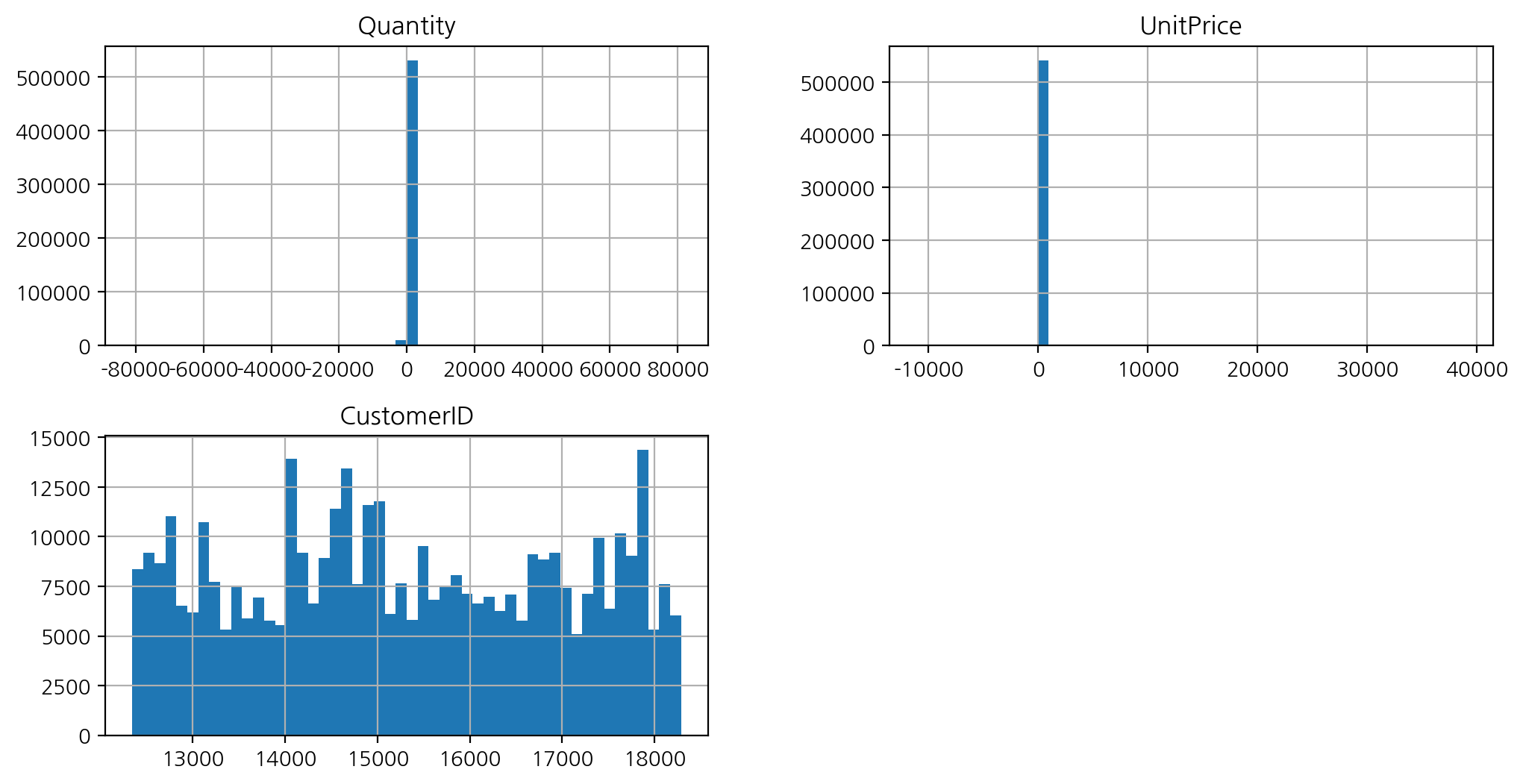
- 이상치 있어보임
전체 주문금액 파생변수 만들기
- (수량 * 금액)으로 전체 금액 계산
df["TotalPrice"] = df['Quantity'] * df['UnitPrice']
df.head(3)
회원 / 비회원 구매
- CustomerID값이 결측치인 값에 대한 Country값을 가져와 빈도수를 구하기
- value_counts() 는 각각의 값이 나온 횟수를 세는 거 -> 자꾸 까먹음…
df[df['CustomerID'].isnull()]['Country'].value_counts()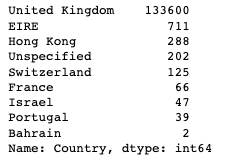
- CustomerID값이 결측치가 아닌 값에 대한 Country값을 가져와 빈도수를 구하기
df[df['CustomerID'] != df['CustomerID'].isnull()]['Country'].value_counts()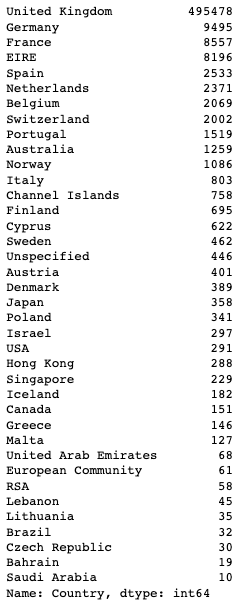
매출액 상위 국가
df.groupby("Country")["TotalPrice"].agg(
["mean", "sum"]).nlargest(10, "sum").style.format("{:,.0f}")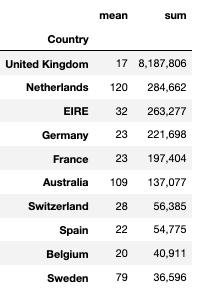
상품
- 판매 빈도가 높은 상품의 판매 빈도, 판매 총 수량, 총 매출액
stock_sale = df.groupby(["StockCode"]).agg({"InvoiceNo": "count",
"Quantity": "sum",
"TotalPrice": "sum"}).nlargest(10, "InvoiceNo")
stock_sale
- 판매 상위 데이터에 'Description' 추가하기
stock_desc = df.loc[df["StockCode"].isin(stock_sale.index), ["StockCode", "Description"]]
stock_desc = stock_desc.drop_duplicates("StockCode").set_index("StockCode")
stock_desc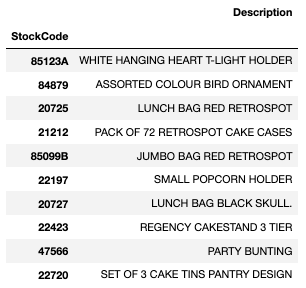
-> StockCode가 같은데 description이 다를 때에는 값이 다르게 들어갈 수 있음
stock_sale["Desc"] = stock_desc
stock_sale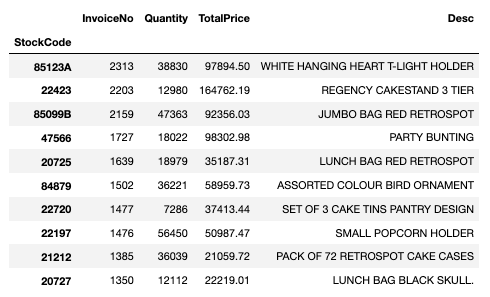
- join 사용
stock_sale.join(stock_desc)
- concat 사용
pd.concat([stock_sale, stock_desc], axis=1)
- merge 사용
stock_sale.merge(stock_desc, left_index=True, right_index=True)- StockCode 가 같은데 StockCode의 Description이 결측치라면 이 방법을 사용했을 때 StockCode의 빈도를 구해서 Description을 추가하면 누락되는 StockCode가 없게 됨
- 다만, 같은 StockCode인데 Description 이 다를 때에는 값이 다르게 들어갈 수도 있기 때문에 주의 필요
구매 취소 비율
- 고객별 구매 취소 비율
- 구매 취소 비율 찾기 위해서는 Cancel 칼럼이 필요
- Quantity(거래당 각 제품의 수량, 이 코드가 '-'로 시작하면 취소를 나타냄)가 0보다 작다면 True, 크다면 False 로
df['Cancel'] = df['Quantity'] < 0df.groupby("CustomerID")["Cancel"].value_counts(normalize=True).unstack()
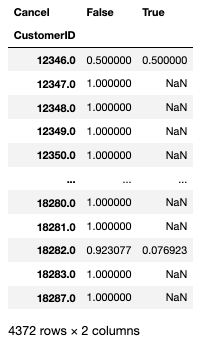
-> .unstack 하는 이유
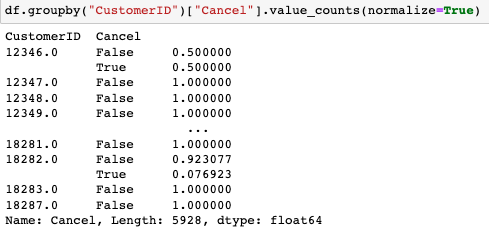

df.groupby("CustomerID")["Cancel"].value_counts().unstack().nlargest(10, True)-> 고객별 구매 취소 빈도 상위 10 => True한 이유는 취소한! 고객을 뽑으려고 한 거니까
- 특정 고객의 구매 건 조회
df[(df["CustomerID"] == 17841) & df['Cancel']]- 제품별 구매 취소 비율
cancel_stock = df.groupby(["StockCode"]).agg({"InvoiceNo":"count", "Cancel": "mean"})- 국가별 구매 취소 비율
cancel_country = df.groupby(['Country']).agg({'InvoiceNo': 'count', 'Cancel': 'mean'})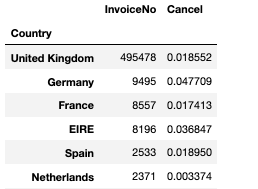
날짜와 시간
1) InvoiceDate를 datetime 모듈을 통해 날짜형식으로 변환
2) year, month, day, dayofweek 를 InvoiceDate에서 추출하여 파생변수로 생성
3) InvoiceDate 에서 앞에서 7개문자만 가져오면([:7]) 연, 월만 따로 생성
4) InvoiceDate 에서 time, hour 에 대한 파생변수도 생성
# InvoiceDate를 datetime 모듈을 통해 날짜형식으로 변환
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])
# year, month, day, dayofweek 를 InvoiceDate에서 추출하여 파생변수로 생성
df["InvoiceYear"] = df["InvoiceDate"].dt.year
df["InvoiceMonth"] = df["InvoiceDate"].dt.month
df["InvoiceDay"] = df["InvoiceDate"].dt.day
df["InvoiceDow"] = df["InvoiceDate"].dt.dayofweek
# InvoiceDate 에서 앞에서 7개문자만 가져오면([:7]) 연, 월만 따로 생성
df["InvoiceYM"] = df["InvoiceDate"].astype(str).str[:7]
# InvoiceDate 에서 time, hour 에 대한 파생변수도 생성
df["InvoiceTime"]= df["InvoiceDate"].dt.time
df["InvoiceHour"]= df["InvoiceDate"].dt.hour
- hist로 전체 수치 변수의 히스토그램 시각화
df.hist(bins = 50, figsize = (12, 12));
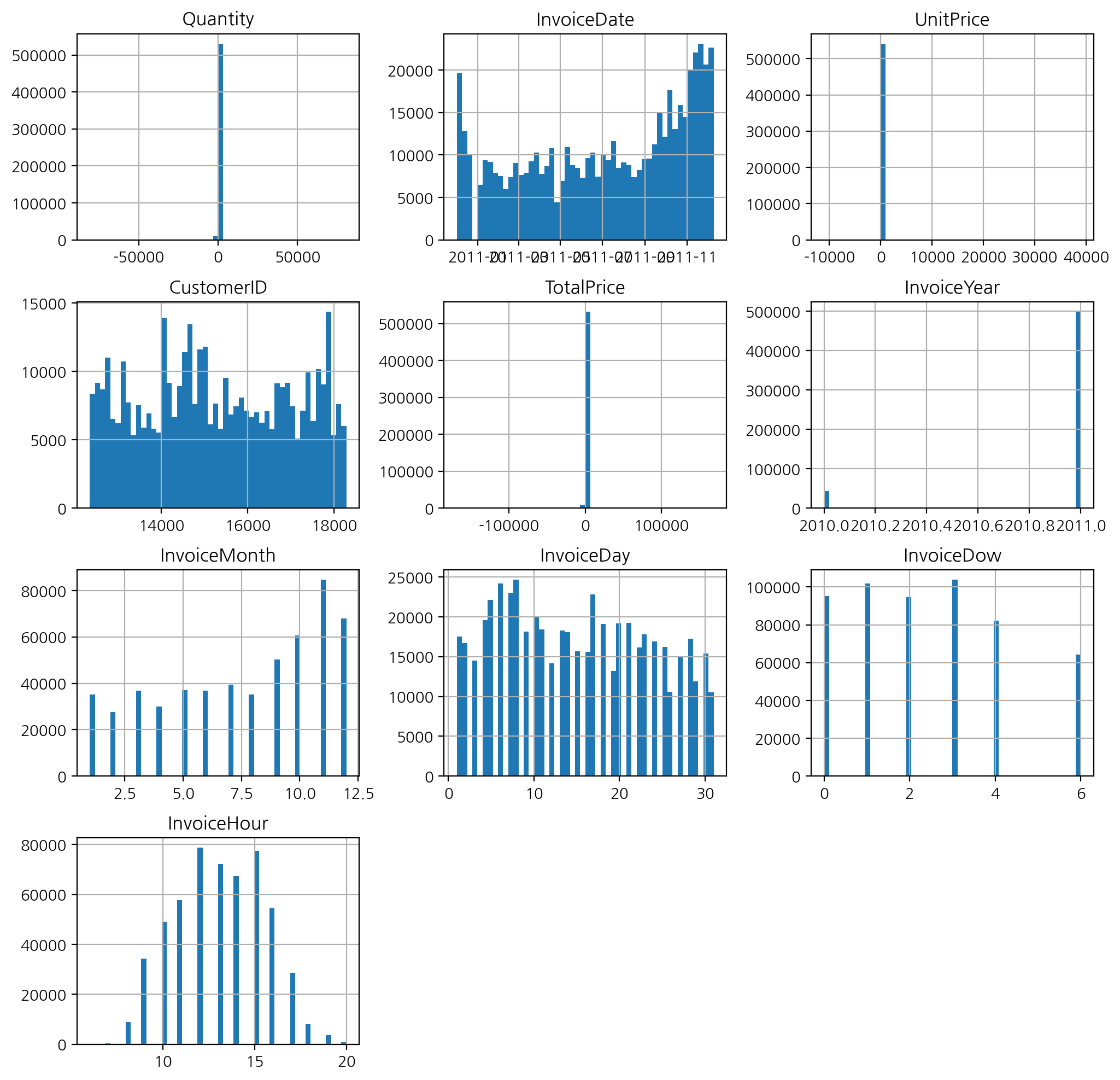
-> 토요일 없음, 새벽 시간 없음을 알 수 있다
- 연도(InvoiceYear)별 구매 빈도수
plt.figure(figsize = (12, 4))
sns.countplot(data = df, x = 'InvoiceYM')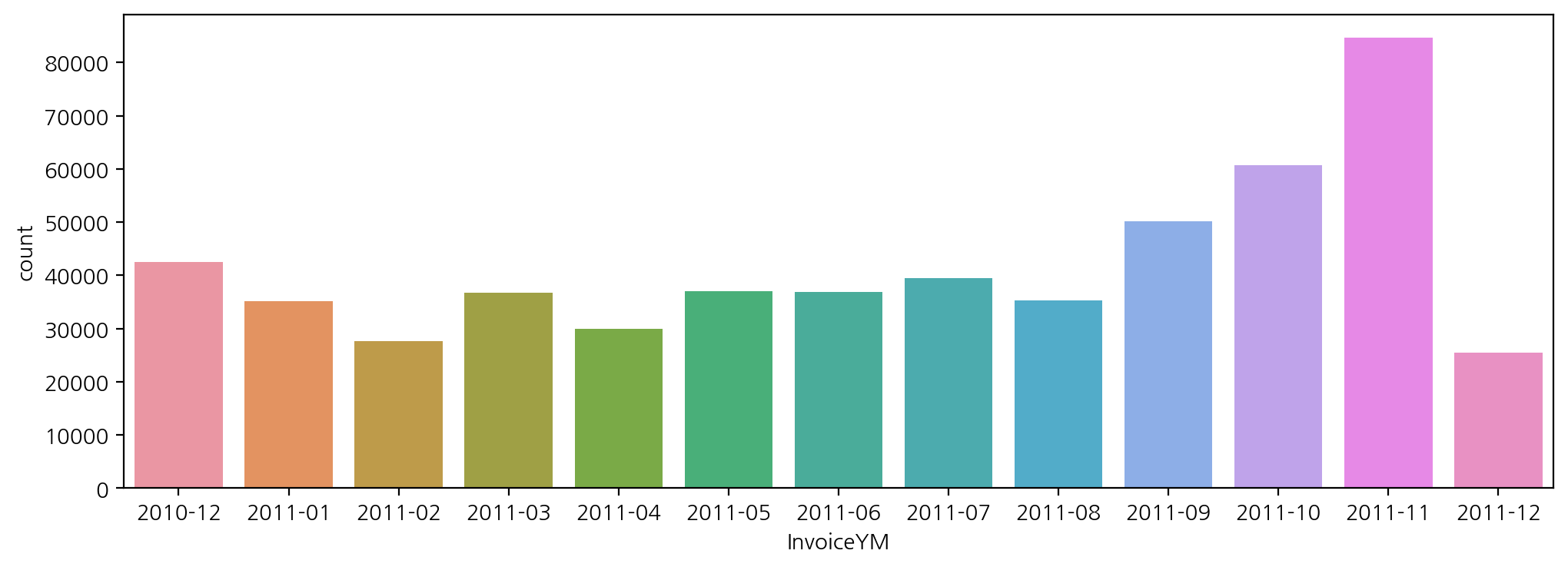
-> 같은 방식으로 월별, 연도-월별 구매 빈도수 시각화 가능
- 요일별 구매와 취소 빈도수
sns.countplot(data=df, x="InvoiceDow", hue="Cancel") ;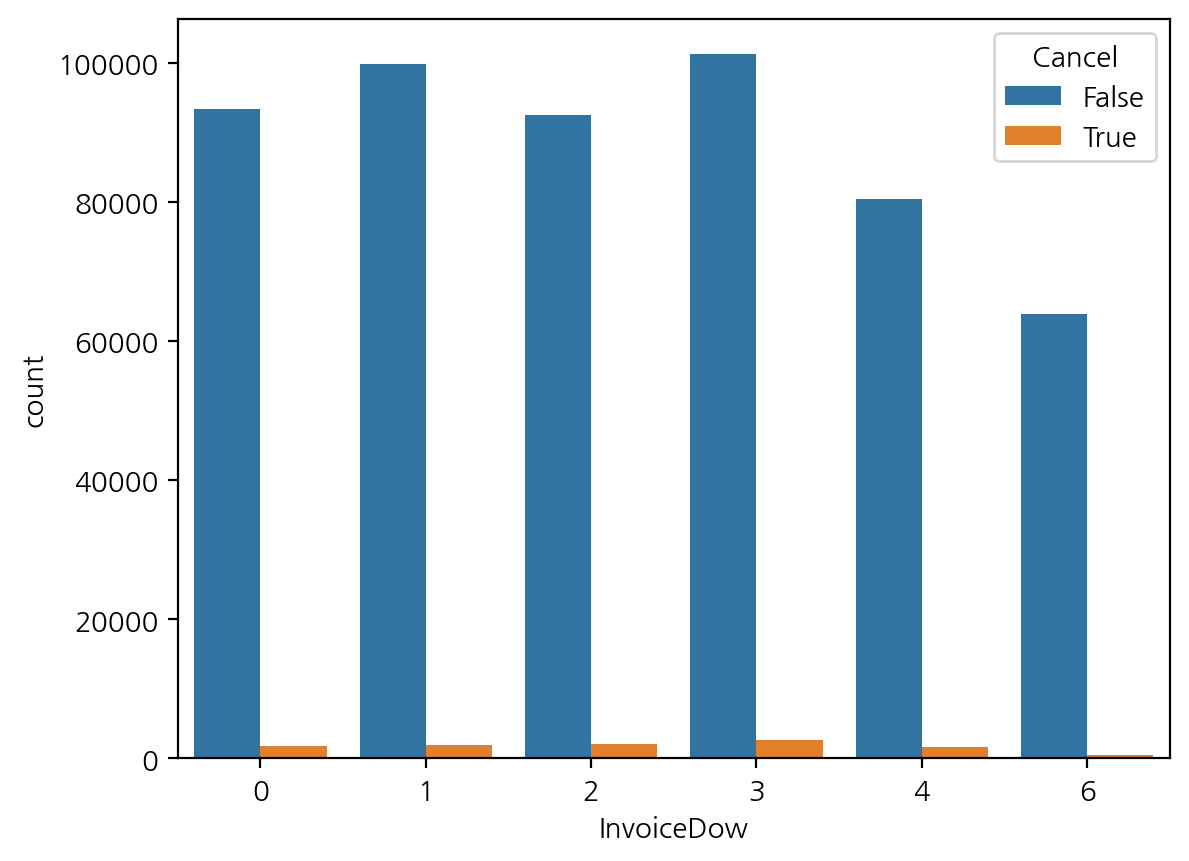
- 요일별 구매 취소 빈도수
plt.title("요일 별 구매 취소")
sns.countplot(data=df[df["Cancel"]], x="InvoiceDow", hue="Cancel") ;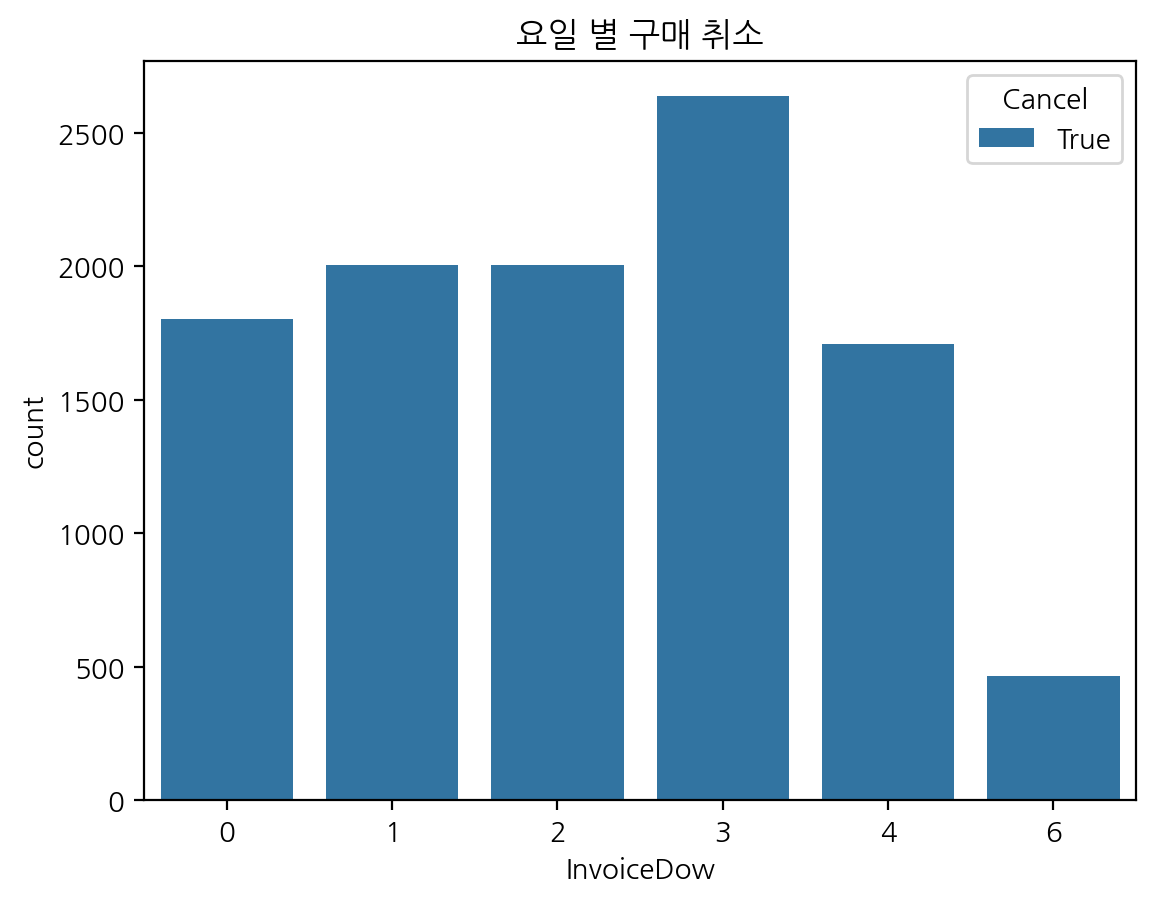
- df['Cancel'] == True 인 데이터로 구매 취소된 값만 추출
-> 012346 말고 월화수목~ 하고 싶다면?
day_name = [w for w in '월화수목금토일']
day_name.remove('토') #토요일 없으니까
dow_count = df['InvoiceDow'].value_counts().sort_index()
dow_count.index = day_name
dow_count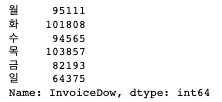
plt.figure(figsize=(12, 4))
dow_count.plot(kind = 'bar', rot = 0)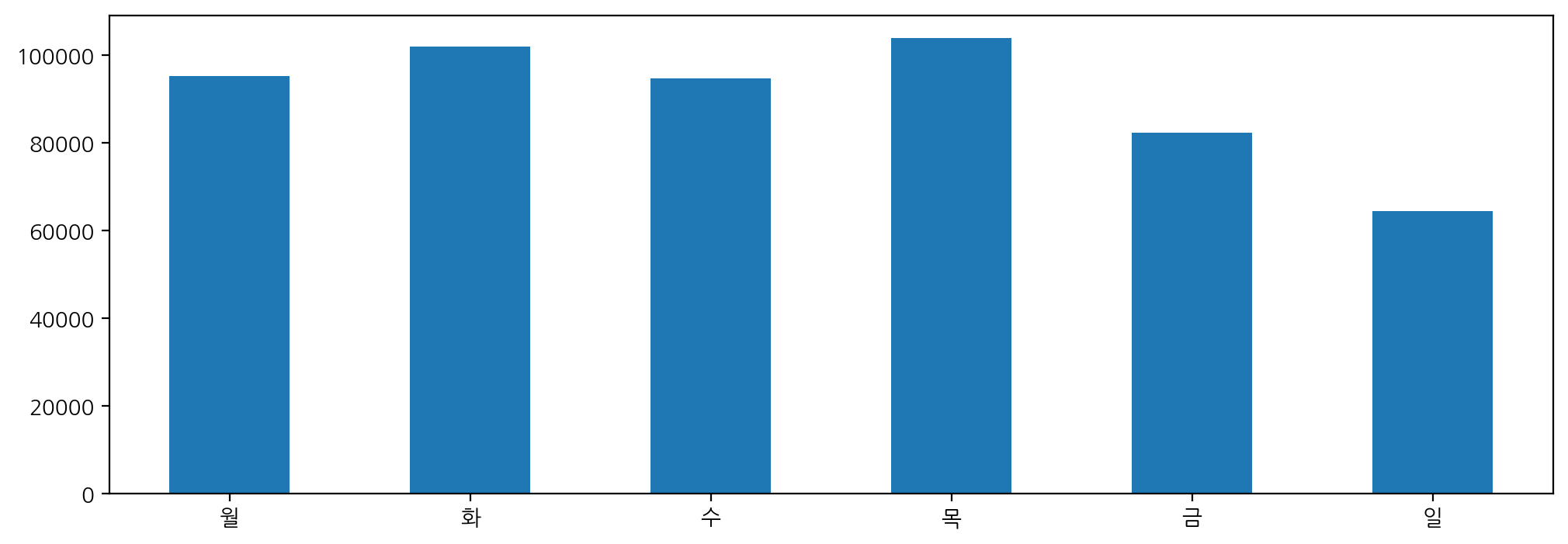
plt.figure(figsize=(12, 4))
dow_count.plot(kind = 'bar', rot = 0, table = True) # table = True 라벨 보이게
plt.xticks([]) ; # 월화수~ 깔끔하게 보여줌 -> 라벨 안 겹치게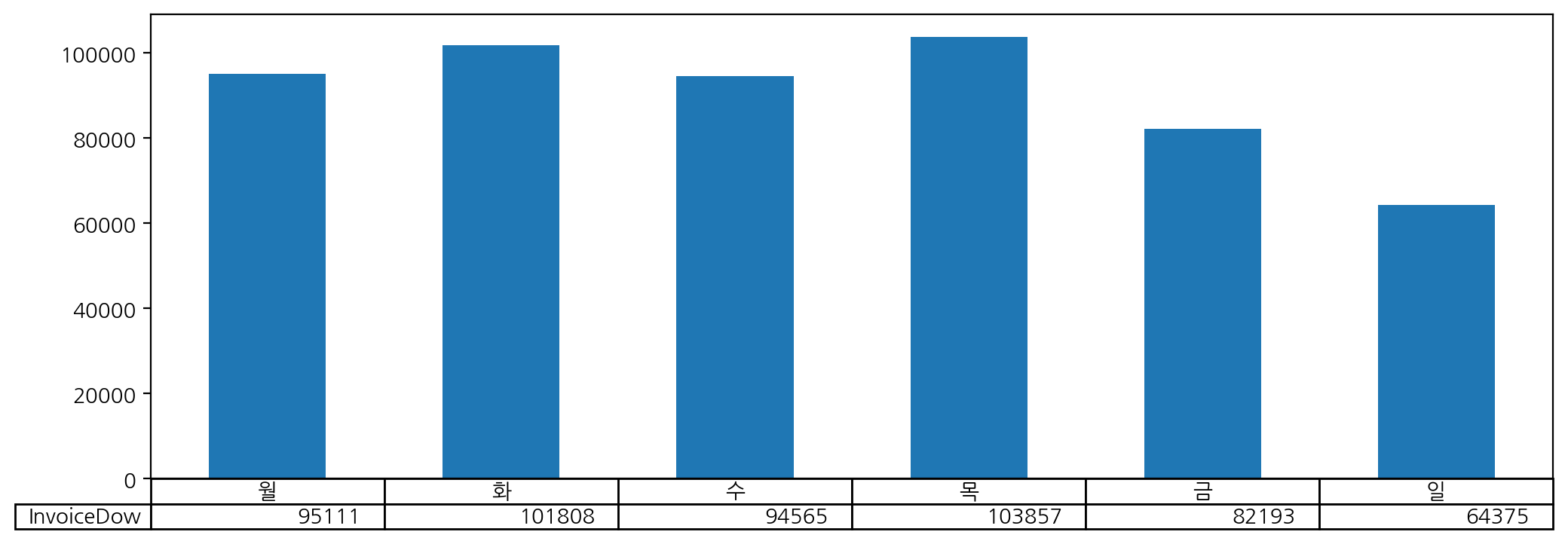
# plt.xticks 활용하는 방법
sns.countplot(data=df, x='InvoiceDow')
plt.xticks(range(len(day_name)), day_name); # 굳이 한글화하는 과정 없이 여기서 한번에 가능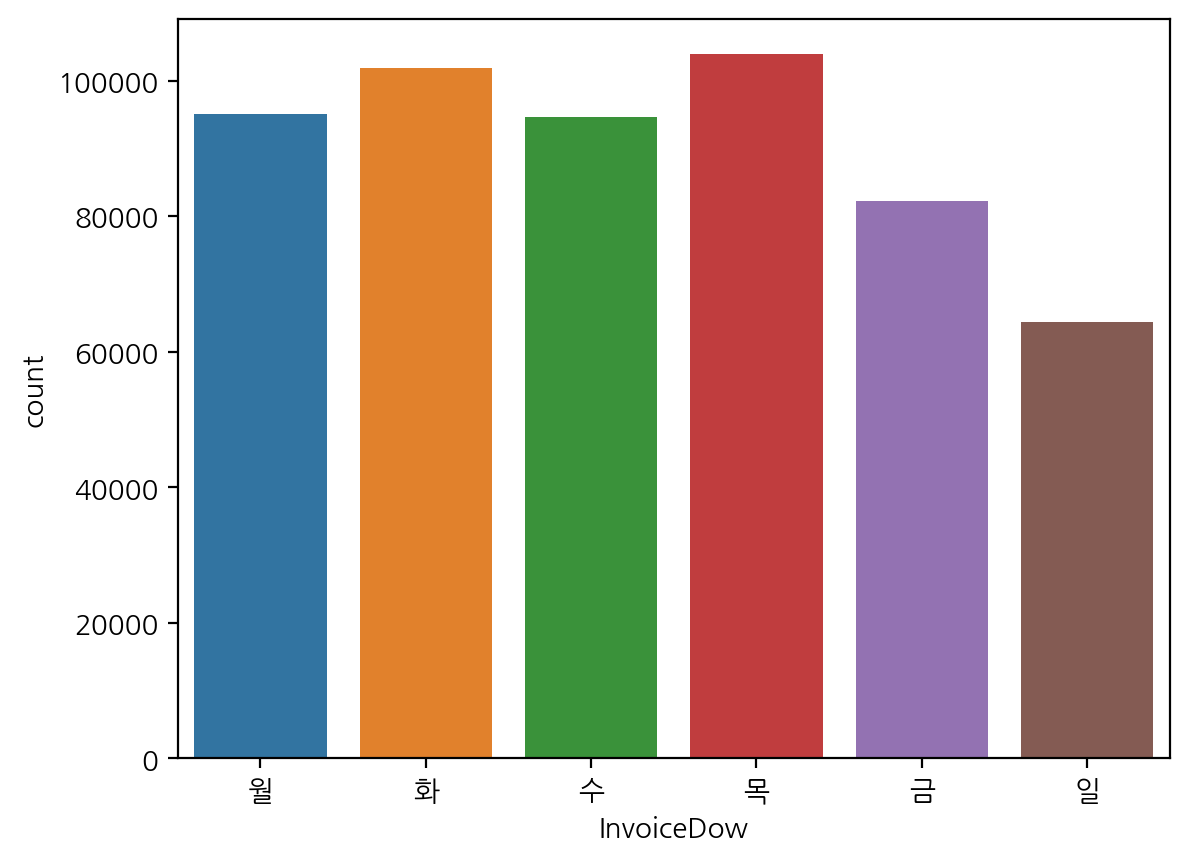
- lambda 활용
df['InvoiceDow_kr'] = df['InvoiceDow'].apply(lambda x : day_name[x])
df = df.sort_values(by = 'InvoiceDow', ascending = True)
sns.countplot(data = df, x = 'InvoiceDow_kr', hue = 'Cancel')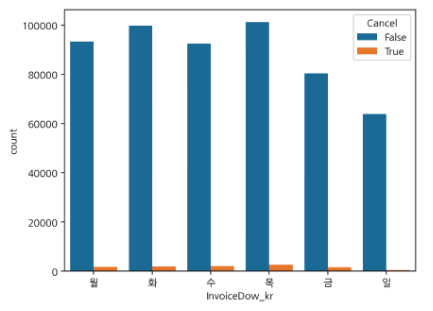
- 시간대별 구매 빈도
plt.figure(figsize=(12, 4))
sns.countplot(data = df, x = 'InvoiceHour')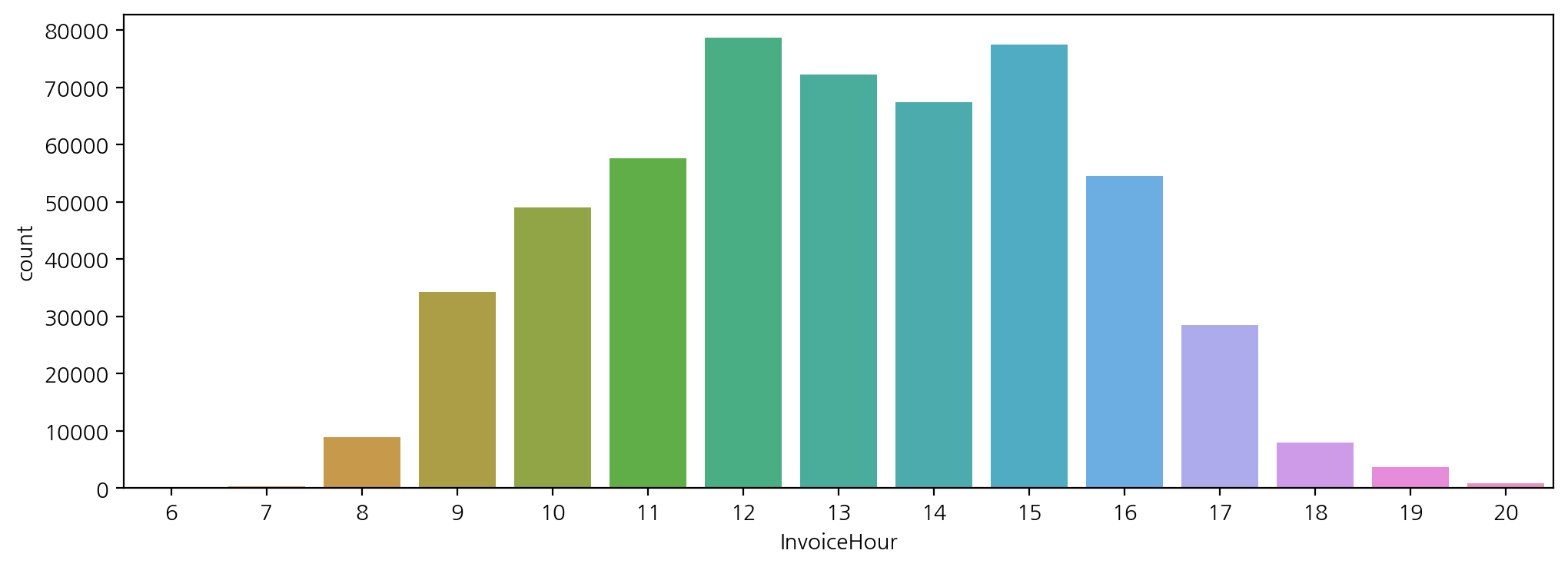
df['InvoiceHour'].value_counts().plot(figsize=(6, 3))
-> 왜 시각화 시간대별로 나오지 않을까? -> 인덱스 순서대로 정리 필요
df['InvoiceHour'].value_counts().sort_index().plot(figsize = (6, 3))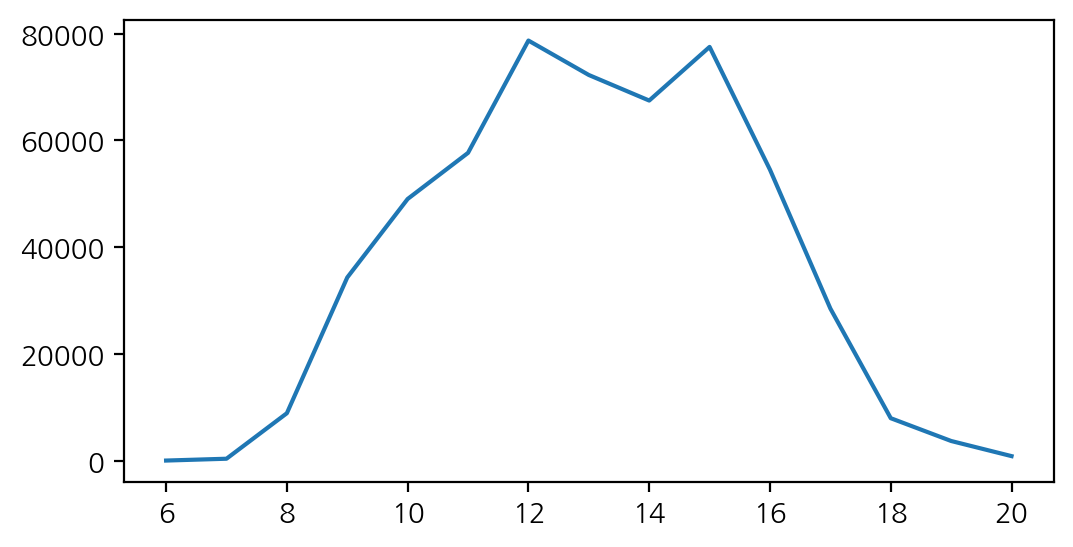
- 시간대별 빈도수
plt.figure(figsize = (12, 4))
sns.pointplot(data = df, x = 'InvoiceHour', y = 'TotalPrice',
errorbar = None, estimator = len).set_title('시간대별 빈도수')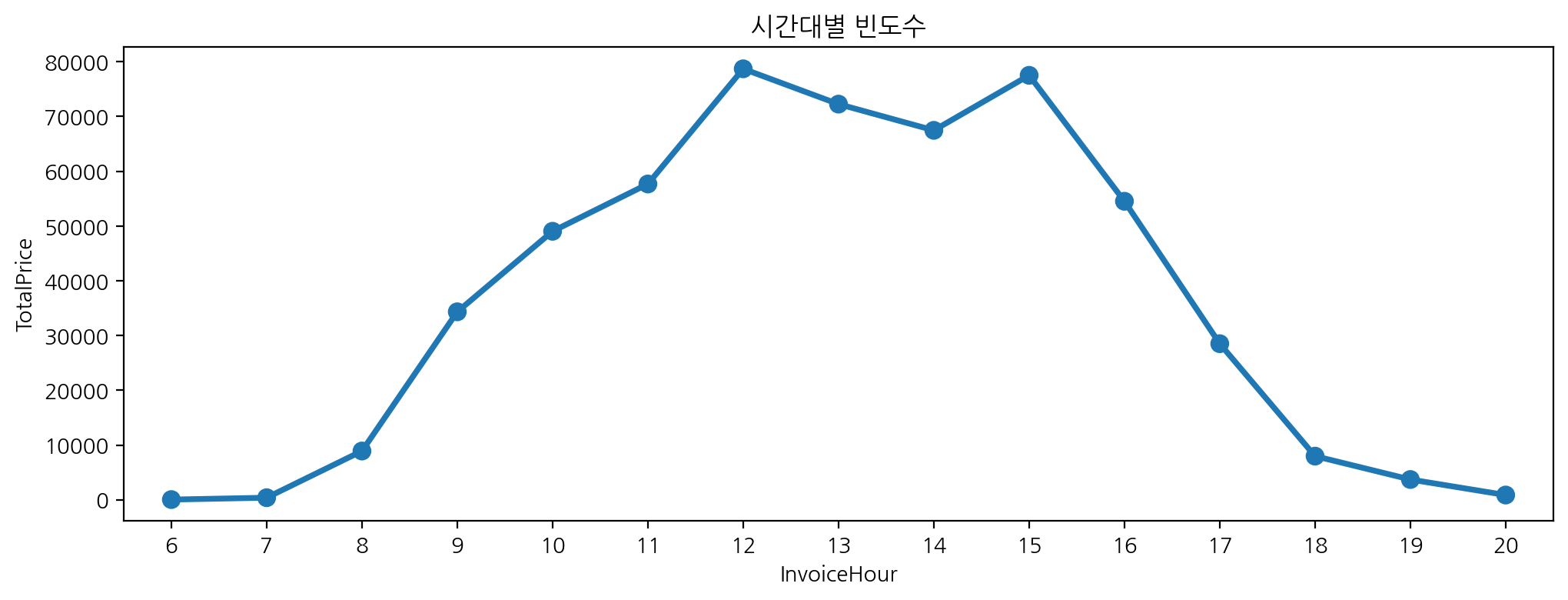
-> 빈도수를 구하려면 y축에 어떤 값이든 넣어줘야해서 수치로 되어 잇는 값 중 하나를 넣음 / errorbar = ci
- 시간대별 합계 매출액
plt.figure(figsize = (12, 4))
sns.pointplot(data = df[df['UnitPrice'] > 0], x = 'InvoiceHour', y = 'TotalPrice',
errorbar = None, estimator = sum).set_title('시간대별 합계 매출액')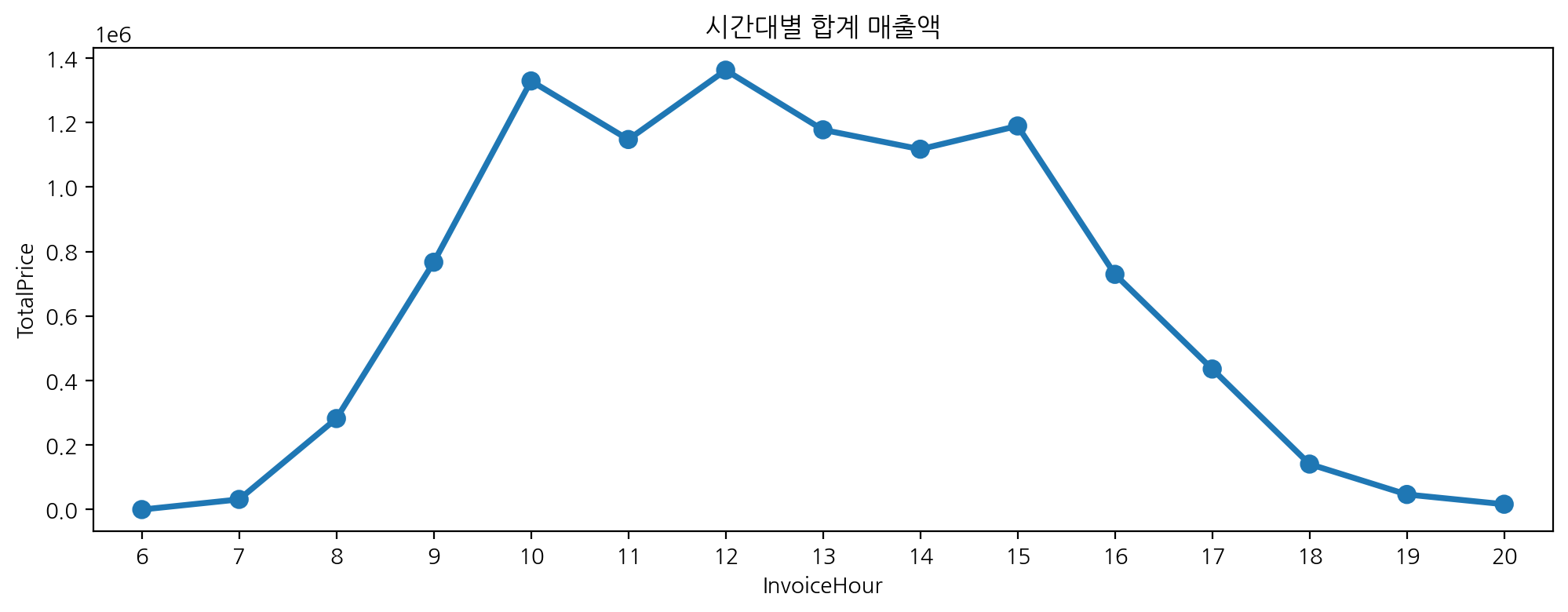
시간-요일별 빈도수
- 시간별, 요일별로 crossab을 통해 구매 빈도수 구하기
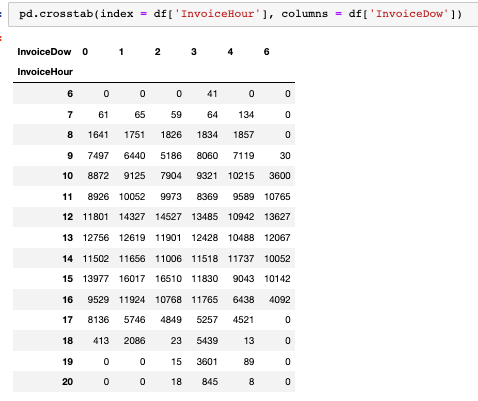
hour_dow = pd.crosstab(index = df['InvoiceHour'], columns = df['InvoiceDow'])
hour_dow.columns = list('월화수목금일')
plt.figure(figsize=(12, 8))
sns.heatmap(hour_dow, cmap = 'Greens', annot = True, fmt = ',.0f')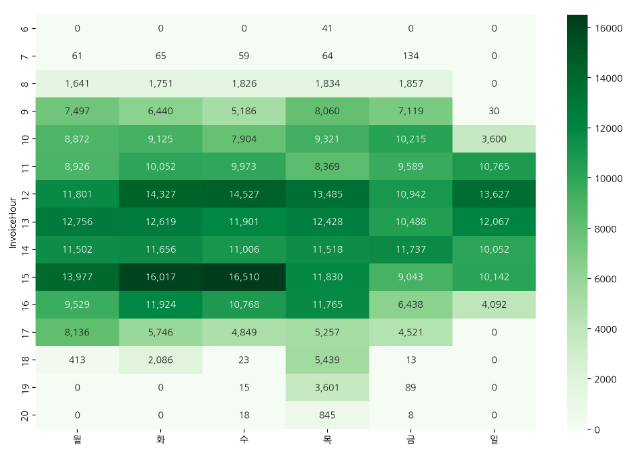
hour_dow.style.background_gradient(cmap = 'summer_r')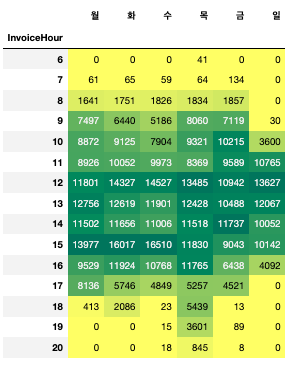
- 시간별_요열별 구매 주문 subplot을 통해 요일별 시각화
hour_dow.plot(figsize = (6, 5), subplots = True) ;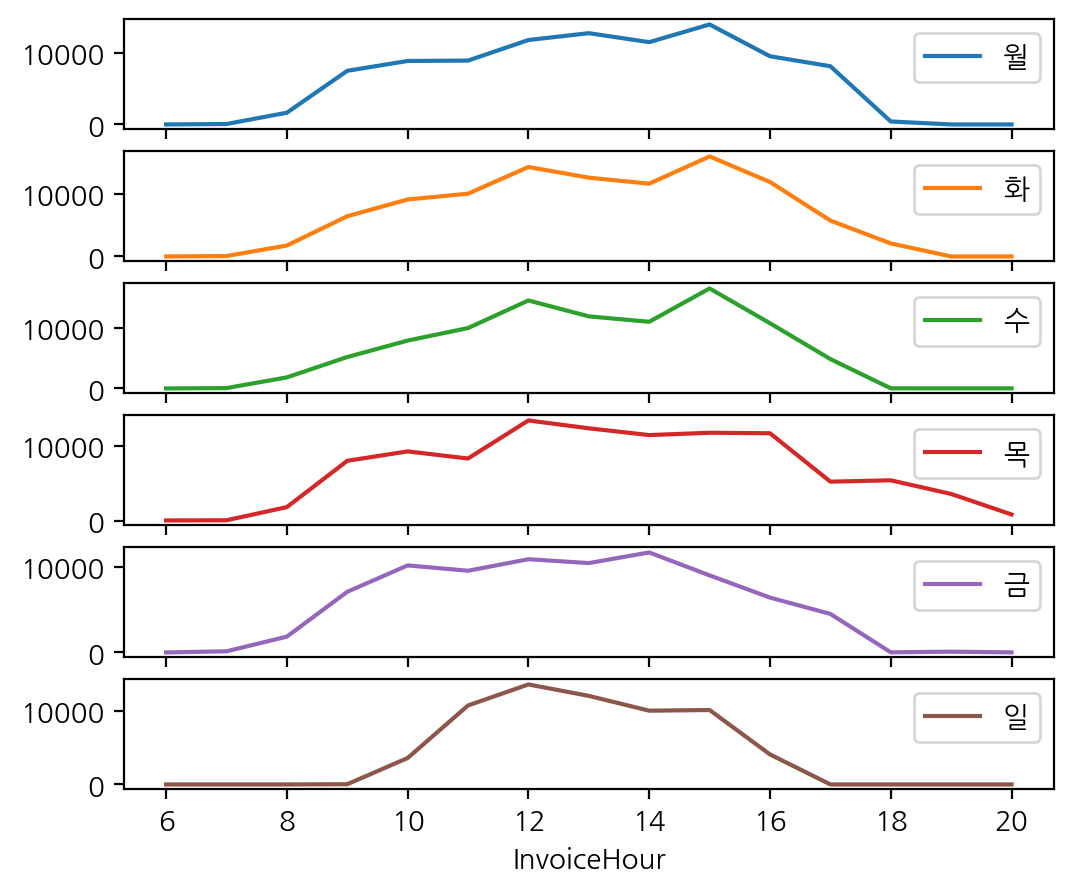
고객 ID가 없는 주문과 취소 주문은 전체 데이터에서 제외
- 'CustomerID' 가 있고(notnull), 'Quantity', 'UnitPrice' 가 0보다 큰 데이터를 가져오기
- 구매하고 취소한 건 중 취소한 건만 제외하고 구매한 건은 남김
- 중복 데이터 제거
df_valid = df[df['CustomerID'].notnull() & (df['Quantity'] > 0) & (df['UnitPrice'] > 0)].copy()
# 중복 데이터 제거
df_valid = df_valid.drop_duplicates().copy()
고객
- ARPU(Average Revenue Per User) :
- 가입한 서비스에 대해 가입자 1명이 특정 기간 동안 지출한 평균 금액
- ARPU = 매출 / 중복을 제외한 순수 활동 사용자 수
- ARPPU(Average Revenue Per Paying User):
- 지불 유저 1명 당 한 달에 결제하는 평균 금액을 산정한 수치
df_valid.columns
arppu = df_valid.groupby(['InvoiceYM']).agg({'CustomerID':'nunique', 'TotalPrice': 'sum'})
arppu['arppu'] = arppu['TotalPrice'] / arppu['CustomerID']
arppu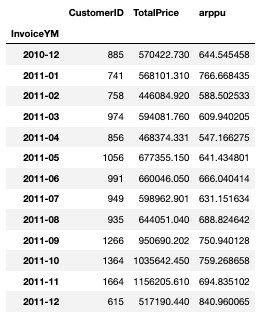
arppu['arppu'].plot(figsize = (12, 4))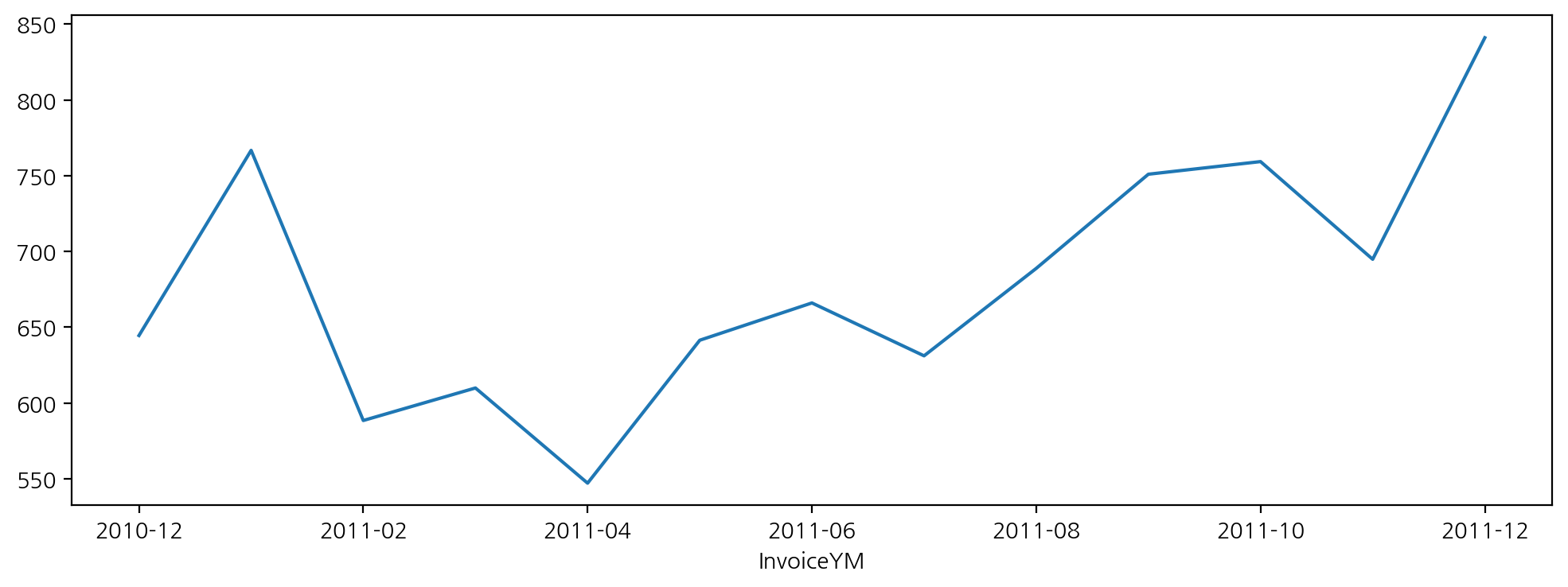
- df_valid(유효고객, 유효주문)내 고객별( CustomerID ) 구매( InvoiceNo ) 빈도수
cust_agg= df_valid.groupby('CustomerID').agg({'InvoiceNo': 'count', 'TotalPrice': ['mean', 'sum']})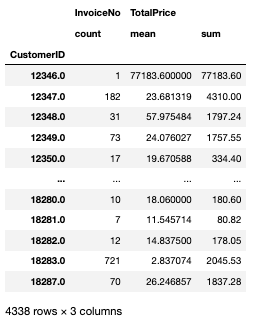
-> 'TotalPrice': ['mean', 'sum'] 딕셔너리는 키 중복을 허용하지 않기 때문에 'total':'mean', 'total':'sum'하면 안 됨
cust_agg.describe()
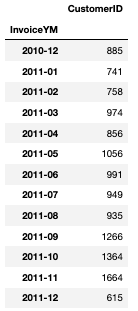
MAU(Monthly Active User)
- 한 달 동안 특정 앱이나 웹사이트를 사용한 총 사용자 수
df_valid.groupby('InvoiceYM').agg({'CustomerID':'nunique'})
df_valid.groupby('InvoiceYM').agg({'CustomerID':'nunique'}).plot(kind = 'bar', rot = 60)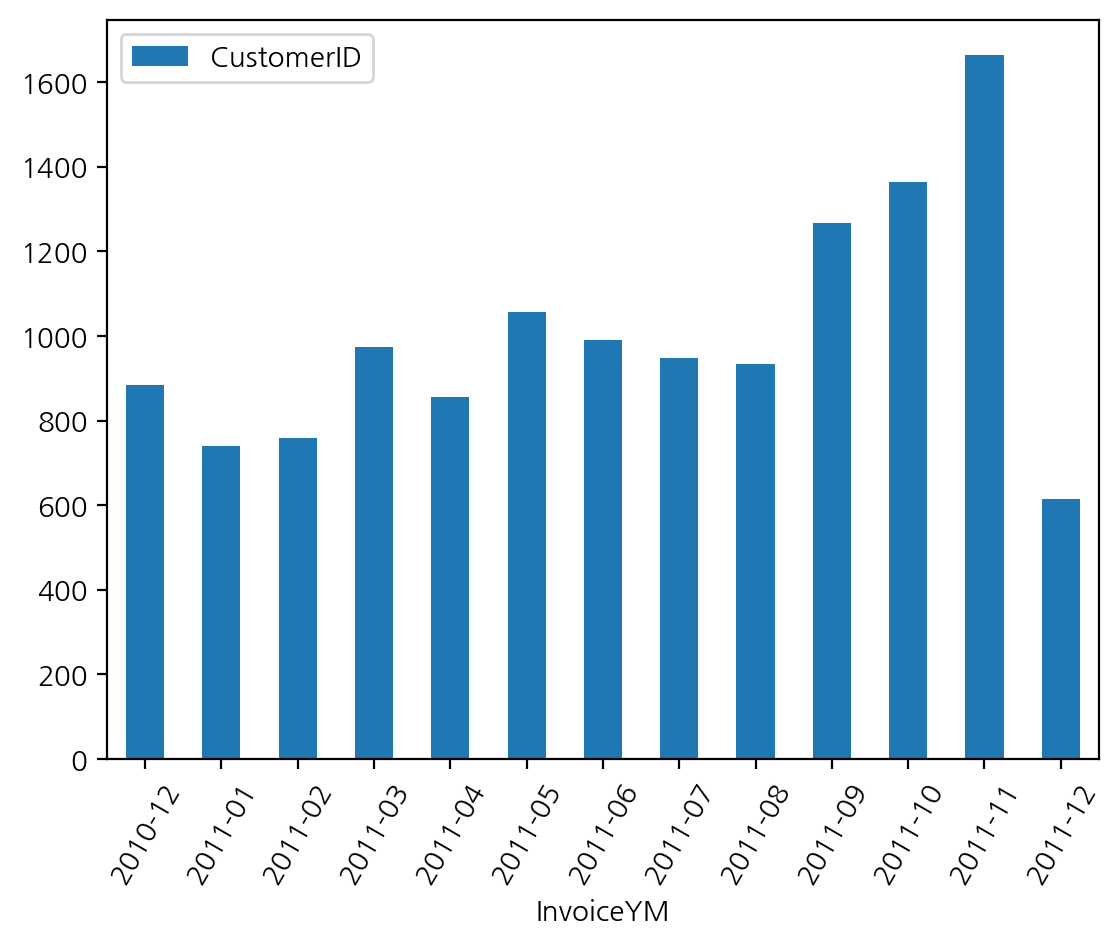
월별, 주문건, 중복을 제외한 주문제품 종류의 수, 고객 수, 총 주문금액
df_valid.groupby("InvoiceYM").agg({"InvoiceNo" : "count",
"StockCode": "nunique",
"CustomerID": "nunique",
"UnitPrice" : "sum",
"Quantity" : "sum",
"TotalPrice" : "sum"
})
월단위 데이터 전처리
df_valid['InvoiceDate1'] = pd.to_datetime(df_valid['InvoiceYM'])-> 월까지만 있는 데이터에 to_datetime하면 2010-12-01 이런 식으로 바뀜
-> 일자를 '1'로 통일하는 이유는 월별 잔존률을 구하기 위해(월 단위, 일은 빼기 위해) -> 파생변수 생성
df_valid['InvoiceDate1'] = pd.to_datetime(df_valid['InvoiceYM'])
df_valid[['InvoiceYM', 'InvoiceDate1']].sample(5)
- 최초 구매일에 InvoiceDate1의 최솟값을 구하여 할당
- 일자가 "1 로 통일되어 있어 " 최근 구매일 - 최초 구매일 "로 첫 구매 후 몇달 후 구매인지를 알 수 있음
df_valid["InvoiceDateMin"] = df_valid.groupby('CustomerID')['InvoiceDate1'].transform('min')
df_valid[["CustomerID", "InvoiceDate", 'InvoiceDate1', "InvoiceDateMin"]].sample(5)
- 연도별 차이( year_diff ), 월별 차이( month_diff )
year_diff = df_valid['InvoiceYear'] - df_valid['InvoiceDateMin'].dt.year
month_diff = df_valid['InvoiceDate1'].dt.month - df_valid['InvoiceDateMin'].dt.month
- " 연도차이 * 12개월 + 월차이 + 1 "로 첫 구매 후 몇달 후 구매인지 알 수 있도록 CohortIndex 변수를 생성
- 2010-12-01부터 2011-12-01의 데이터를 기반으로 진행되어 CohortIndex 변수의 최소값은 1이며, 최대값 13
df_valid["CohortIndex"] = year_diff * 12 + month_diff + 1
df_valid["CohortIndex"].value_counts()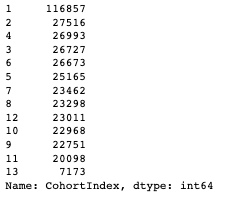
plt.figure(figsize=(12, 4))
sns.countplot(data = df_valid, x = 'CohortIndex')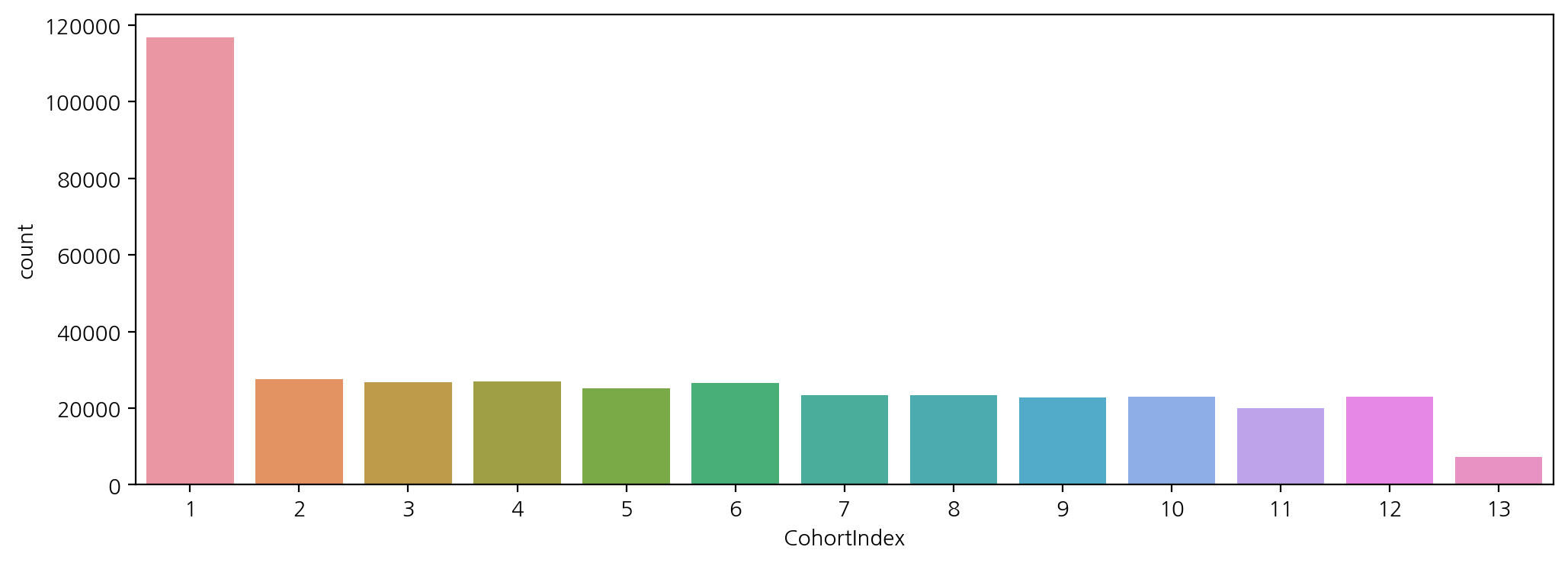
잔존 빈도 구하기
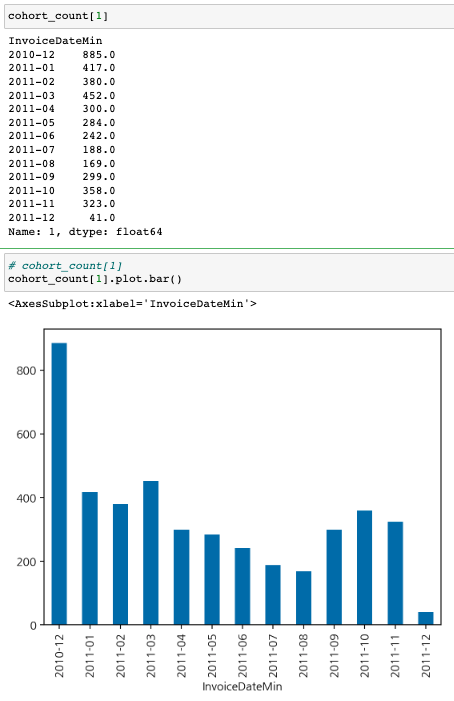
cohort_count = df_valid.groupby(['InvoiceDateMin', 'CohortIndex'])['CustomerID'].nunique().unstack()
cohort_count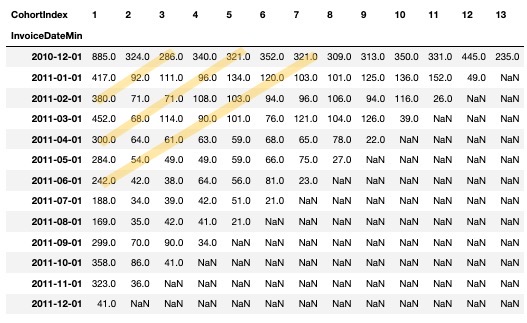
-> 대각선끼리 같은 달
-> 해당 월에 처음 온 사람이 얼마나 남았는지 / 10년 12월에 처음 온 사람들이 그 다음달에는 324명 잔존함
-> 서비스에 따라 로그인한 사용자의 수를 기준으로 하는 등 다양한 기준으로 리텐션(잔존율) 구함
cohort_count.index = cohort_count.index.astype(str).str[:7]
plt.figure(figsize=(12, 8))
sns.heatmap(cohort_count, annot = True, cmap = 'summer_r', fmt = ',.0f')
- 월별 신규 유입 고객수
- Acqusition
잔존율 구하기
- 가입한 달을 1로 나누면 잔존율을 구할 수 있음ㅇ
- div를 통해 구하며 axis = 0으로 설정하면 첫달을 기준으로 나머지 달을 나눔
cohort_norm = cohort_count.div(cohort_count[1], axis = 0).round(2)
cohort_norm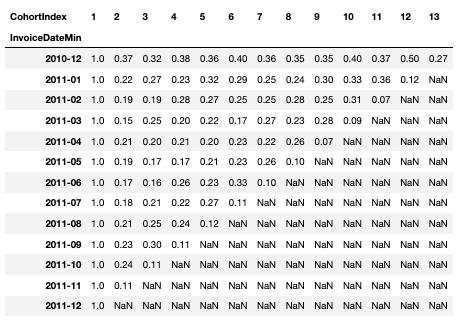
plt.figure(figsize=(12, 8))
sns.heatmap(cohort_norm, annot = True, cmap = 'Blues')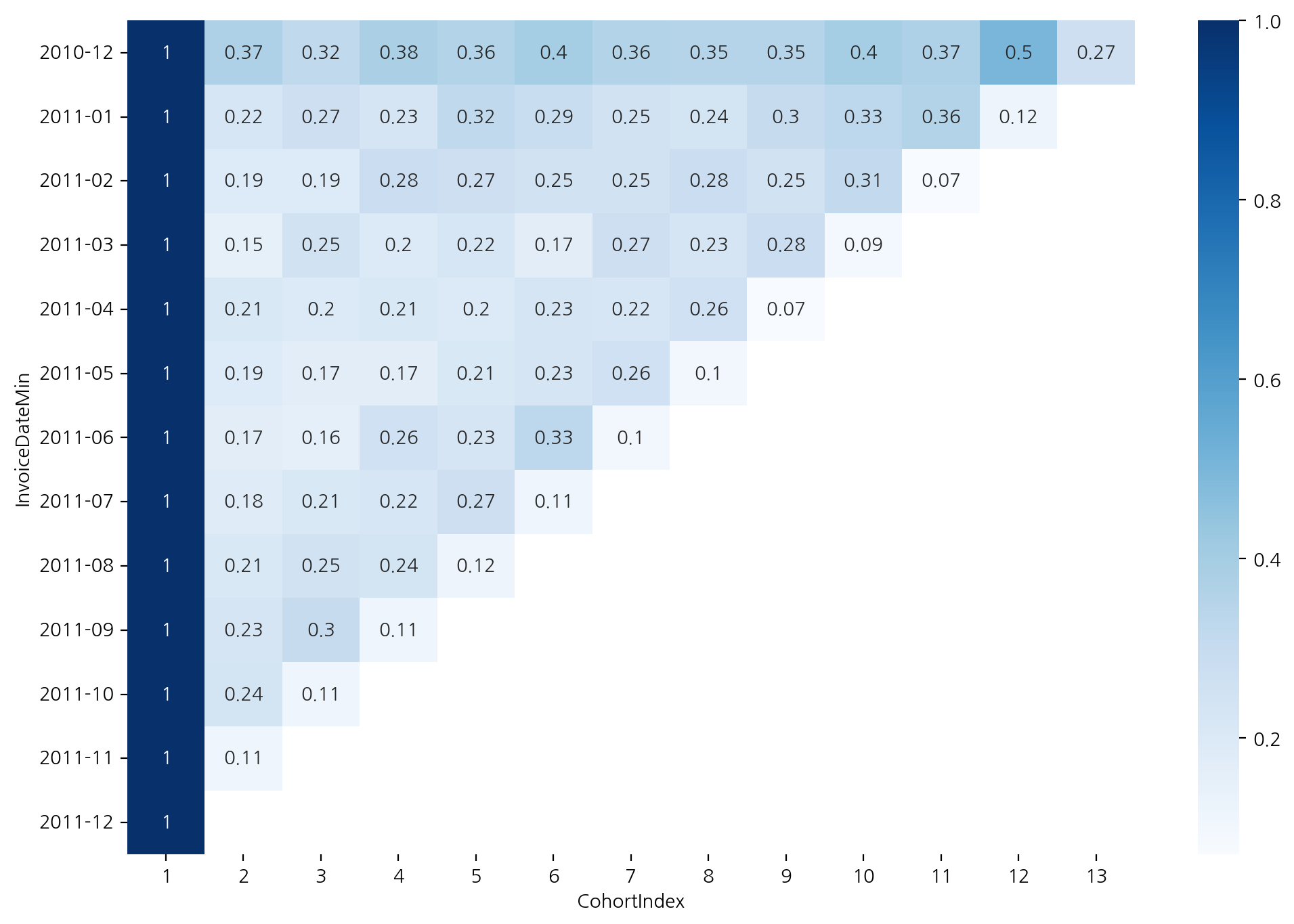
-> 11월은 전달에 비해 다 늘었음 => 무슨 이벤트가 있지 않았을까? 추측 가능
- 상품 -> drop_duplicates()
StockCode가 같더라도 Description이 다른 경우가 있던데 그 부분은 무시하고 하나만 남기는 것인가?
-
keep: "Literal['first', 'last', False]" = 'first', 어떤 상황에서는 처음 것을 남기고 어떤 상황에서는 최근 데이터를 남기기도 함
- 이건 비즈니스 상황에 따라 다르게 판단
- 예를 들어 설문조사를 했다면 최근 조사가 더 신뢰있다고 판단할 때 중복된 조사에서 최근 데이터를 남기기도 하는데 처음 남긴 데이터가 중요하다면 처음 것을 사용하게 할수도 있음
- Series.dt
https://pandas.pydata.org/docs/reference/series.html
Series — pandas 1.5.3 documentation
Warning Series.attrs is considered experimental and may change without warning.
pandas.pydata.org

'AI SCHOOL > Python' 카테고리의 다른 글
| [Python] 코딩도장 (0) | 2023.03.31 |
|---|---|
| [Python] 비즈니스 데이터 분석(RFM) (0) | 2023.03.08 |
| [Python] 전국 신규 민간 아파트 분양가격 동향 (0) | 2023.02.09 |
| [Python] Plotly / FinanceDataReader (1) | 2023.02.02 |
| [Python] FinanceDataReader - 2 (0) | 2023.02.01 |