API 사용 이유
- 허락된 사람에게만 정보를 제공하고 누가 수집해 갔는지 알기 위해
= 유료로 데이터를 판매하고 있는 사이트는 데이터 용량 등에 따라 과금
- 공공데이터는 실시간성으로 제공하고자 하는 데이터의 경우 예) 부동산실거래가 정보 등
- 특정 사이트에 무리하게 네트워크 요청을 보내면 서버에 무리가 갈 수 있
예) 만약에 50명이 특정 카페24의 작은 쇼핑몰에 요청을 한번에 보내면 서버를 다운시킬 수도 있음
API용 서버를 따로 두게 되면 데이터를 무리하게 읽어 갔을 때 운영하고 있는 서비스의 서버에 무리가 가지 않게 분리해서 운영할 수 있습니다. 네이버, 카카오, 유튜브 등은 API를 따로 제공
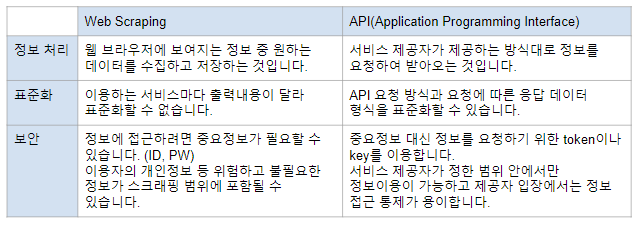
Web Scraping vs API
- 웹 스크래핑은 브라우저에 보여지는 정보를 사용자가 자동화된 툴로 수집하는 것
- API는 Application Programming Interface의 줄임말로, 서로 다른 소프트웨어끼리 서비스를 제공하기 위한 사양을 의미
-> 여기서는 서버에 정보를 요청하기 위한 방법
etf 는 공식적으로 공개하는 api 아니지만 우리가 확인해보니까 api였던 것임
Open API
API란?
- Application Programming Interface의 약어입니다.
- 서로 다른 사양의 컴퓨터나 컴퓨터 프로그램이 데이터를 주고받을 수 있도록 하는 도구입니다.
- 예제에서는 사용자가 서울 열린데이터 광장의 서버에서 데이터를 요청할 수 있게 합니다.
- https://ko.wikipedia.org/wiki/API
Open API
- Open API는 개발자라면 누구나 사용할 수 있도록 공개된 API를 의미합니다.
- 서울 열린데이터 광장에서는 Open API를 제공하여 사용자들이 데이터에 편리하게 접근할 수 있도록 하고 있습니다.
| 120상담정보 | 서울시 다산콜센터 자주묻는질문 목록 조회 | |
| 서울시 및 자치구에서 수행하는 정책 | ||
# pandas : 파이썬에서 사용할 수 있는 엑셀과 유사한 데이터분석 도구입니다.
# requests : 매우 작은 브라우저로 웹사이트의 내용과 정보를 불러옵니다.
# BeautifulSoup : request로 가져온 웹사이트의 html 태그를 찾기 위해 사용합니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs# "서울시 다산콜센터 자주묻는질문 목록" 데이터의 메타정보를 담은 페이지를 url 변수에 담아줍니다.
# pd.read_html 을 통해 해당 URL의 table 정보를 읽어옵니다.
# DataFrame의 0행을 인덱스로 만듭니다.
# 행을 열으로, 열을 행으로 작성하여 바꾸어줍니다. pandas.DataFrame.transpose와 동일합니다.
api_document_url = "https://data.seoul.go.kr/dataList/OA-1127/S/1/datasetView.do"
df_api_doc = pd.read_html(api_document_url)[2].set_index(0).T
df_api_doc
-> 이 페이지는 그냥 읽어와 보는 것임 api연습 x
수집할 URL
인증키 설정 : 인증키 설정 => 보통은 공개된 곳에 인증키를 적기보다는 별도의 파일로 관리합니다.
auth_key
# 발급받은 API 키를 auth_key 변수에 담아줍니다.
# 요청할 url에 API 키를 삽입하여 faq_url 변수에 담아줍니다.
auth_key = '####'
faq_url = f"http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchFAQService/1/999/F"HTTP 요청으로 목록 수집
# API 키를 이용해 결과를 받아옵니다.
result = requests.get(faq_url)
result.text
XML데이터 해석
XML이란?
- eXtensible Markup Language의 약어
- 인터넷 상에서 구조화된 데이터를 전송하기 위해 만들어진 형식
- XML은 주로 다른 종류의 시스템, 특히 인터넷에 연결된 시스템끼리 데이터를 쉽게 주고 받을 수 있게 하여 HTML의 한계를 극복할 목적으로 만들어짐
https://ko.wikipedia.org/wiki/XML
# 변수 df_list_all에 pandas의 xml 읽어오기 기능을 이용해 result의 text를 읽어옵니다.
# df_list_all를 확인합니다.
df_list_all = pd.read_xml(result.text)
df_list_all
-> 전처리 필요할 것으로 보임
pd.read_xml 로 안 되면 bs사용해서 하나하나 따야함
-> 메타정보와 일반 정보가 섞여있음
데이터 살펴보기
데이터 전처리 계획
- list_total_count, CODE, MESSAGE는 request에 대한 정보가 담겨있는 열입니다.
- 나머지는 request한 요청에 대한 내용이 담겨있는 열입니다.
- 성질이 전혀 다른 열이 한 데이터프레임에 담겨 있어 결측치가 많이 생겼습니다.
- 현재 형태에서는 불필요한 NaN이나 None값이 불필요하게 많이 존재합니다.
- 정보의 종류의 따라 두 개의 데이터프레임으로 분리하겠습니다.
- list_total_count, CODE, MESSAGE는 request에 대한 상태를 나타내는 status 데이터프레임으로 분리하겠습니다.
- 나머지는 요청에 대한 내용을 담고 있는 content 데이터프레임으로 분리하겠습니다.
- FAQ_SEQNO와 LCODE 열은 각각 FAQ에 대한 코드명으로, 정수형으로 나타내는 것이 더 적절할 것 같습니다.
- UPDATE_YMDHMS 열은 보기 더 편해졌지만, 아직도 날짜 형태 데이터가 아니라 실수형 데이터입니다.
- UPDATE_YMDHMS를 날짜형 데이터로 바꿔주겠습니다.
메타정보
# df_list_status 변수에 list_total_count, CODE, MESSAGE에서 필요한 정보만 담은 데이터프레임을 담습니다.
# df_list_status를 확인합니다.
df_list_status = df_list_all.iloc[:2, :3]
df_list_status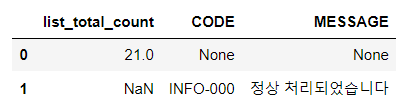
# df_list 변수에 나머지 열을 담은 데이터프레임을 담습니다.
# df_list 를 확인합니다.
df_list = df_list_all.iloc[2:, 3:]
df_list
# df_list 의 인덱스가 2부터 시작합니다. 인덱스를 초기화합니다.
# FAQ_SEQNO을 정수형 데이터로 변경합니다.
# LCODE를 정수형 데이터로 변경합니다.
# UPDATE_YMDHMS를 문자열 데이터로 변경하고 13번째 문자까지만 갖도록 slicing 합니다.
# UPDATE_YMDHMS를 pandas의 날짜 데이터 형식으로 변경합니다.
# df_list 를 확인합니다.
# df_list
df_list['UPDATE_YMDHMS'] 를 str로 바꿔주고 뒤에 없애고 그 다음 그걸 날짜 데이터 형식으로 바꿈
df_list["UPDATE_YMD"] = pd.to_datetime(df_list['UPDATE_YMDHMS'].astype(str).str[:14])
df_list
내용 수집 연습
서버에서 제공하는 sample code를 통해 FAQ 하나하나에 대한 정보를 불러오는 연습을 해보겠습니다.
http://openapi.seoul.go.kr:8088/sample/xml/SearchDetailsFAQService/1/5/F/
URL 에 들어가는 다음 문자의 의미입니다.
F : FAQ
S : 서울시 업무매뉴얼
J : 자치구 업무매뉴얼
# 일련번호 289435를 faq_no 변수에 담아줍니다.
# 요청할 url에 일련번호 faq_no를 삽입하여 detail_url 변수에 담아줍니다.
faq_no = 289435
detail_url = f"http://openapi.seoul.go.kr:8088/sample/xml/SearchDetailsFAQService/1/5/F/{faq_no}"
detail_url-> 얘는 샘플 활용한거임 (API)
'http://openapi.seoul.go.kr:8088/sample/xml/SearchDetailsFAQService/1/5/F/289435'# pandas의 xml 읽어오기 기능을 이용해 result의 text를 읽어오겠습니다.
cont = pd.read_xml(detail_url)
cont
특정내용 읽어오기
# df_list의 첫 행에 해당하는 내용을 읽어오겠습니다.
# FAQ_TP에 df_list의 첫 행의 FAQ_TP의 값을 담아줍니다.
# FAQ_SEQNO df_list의 첫 행의 FAQ_SEQNO 값을 담아줍니다.
# FAQ_TP
# FAQ_SEQNO
df_list.iloc[0]["FAQ_TP"]'F'
# detail_url에 값을 요청할 url 정보를 담아줍니다.
detail_url = f'http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchDetailsFAQService/1/1/{FAQ_TP}/{FAQ_SEQNO}/'# pandas의 xml 읽어오기 기능을 이용해 result의 text를 읽어옵니다.
result = pd.read_xml(detail_url)
result.iloc[-1]["ANSWER"]
내용 수집 함수 만들기
# 특정 FAQ의 내용을 읽어오는 함수를 작성합니다.
def get_content(FAQ_SEQNO):
'''FAQ_SEQNO로 ANSWER를 반환하는 함수
'''
detail_url = f'http://openAPI.seoul.go.kr:8088/{auth_key}/xml/SearchDetailsFAQService/1/1/F/{FAQ_SEQNO}/'
result = pd.read_xml(detail_url)
answer = result.iloc[-1]["ANSWER"]
return answerfrom tqdm import tqdm
tqdm.pandas()
df_list["ANSWER"] = df_list["FAQ_SEQNO"].progress_map(get_content)
df_list
'AI SCHOOL > Python' 카테고리의 다른 글
| [Python] 서울 코로나 데이터 분석(EDA) - 2 (0) | 2023.01.31 |
|---|---|
| [Python] 서울 코로나 데이터 분석(EDA) - 1 (0) | 2023.01.30 |
| [Python] 네이버 금융 ETF 수집, json 데이터 수집 (0) | 2023.01.24 |
| [Python] 다산콜센터 주요 민원 내용 수집(2) (0) | 2023.01.24 |
| [Python] 대통령연설기록 수집 - 2 (연설 내 가져오기) (0) | 2023.01.22 |