Decision Tree의 단점
- overfitting: Decision tree는 학습 데이터에 과도하게 학습할 수 있어서, 과적합(overfitting)이 발생하기 쉬움
- 결정 경계의 수직/수평선 문제: Decision tree는 분류 경계를 수직 또는 수평선으로만 설정하기 때문에, 데이터가 대각선 방향으로 구분되는 경우 결정 경계를 잘 파악하지 못할 수 있음
- 불균형 데이터셋 처리 문제
- 연속형 변수 처리 문제: Decision tree는 연속형 변수를 처리하기에 적합하지 않습니다. 일반적으로 연속형 변수를 범주형 변수로 변환한 후에 사용해야 함
-> 이러한 단점 보완하기 위해 앙상블 기법 중 하나인 배깅 기법 사용한 랜덤포레스트 사용
Random Forest
# RandomForestClassifier 모델 불러오기
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42)
# 학습하기
model.fit(X_train, y_train)
# 예측하기
y_predict = model.predict(X_test)
# 정확도 측정하기
(y_test == y_predict).mean()
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
데이터셋 확인 및 전처리
데이터셋: Telco Customer Churn - https://www.kaggle.com/blastchar/telco-customer-churn / 고객 유지를 위한 행동 예측, 인구 통계 정보, 구독 서비스, 최근 한 달 이내에 탈퇴한 고객(Churn) 정보 등을 담고 있음
# 데이터 로드
df = pd.read_csv("https://bit.ly/telco-csv", index_col="customerID")
# 숫자형으로
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"], errors="coerce")
# 결측치 제거
df = df.dropna()
학습, 예측 데이터셋 나누기
# 정답값이자 예측해야 될 값
label_name = 'Churn'
X_raw = df.drop(columns = label_name)
y = df[label_name]- One-hot-Encoding
- 범주형 변수의 모든 값을 이진수(binary)로 표현하는 방법
- 예를 들어, 색상이 빨강, 파랑, 노랑으로 구분되는 경우, One hot encoding을 사용하면 각 색상을 0 또는 1의 값으로 변환할 수 있다.
- 즉, 빨강은 [1, 0, 0], 파랑은 [0, 1, 0], 노랑은 [0, 0, 1]과 같은 방식으로 범주형 변수를 변환
- 결측치를 고려하지 않음 -> 결측치를 원핫인코딩에 반영하고자 하면 문자 데이터로 '없음'값을 만들어주어야 함
장점 : 모든 머신러닝 알고리즘에서 사용 가능하다 범주형 변수를 수치형 변수로 변환해 줌 -> 모델이 변수 간 상관관계를 파악할 수 있다. 범주형 변수의 카테고리 수가 많아져도 적용할 수 있다.
단점 : 카테고리 수가 많은 경우, 변수의 차원이 늘어남. -> 차원의 저주 문제 / 모델 학습 속도 저하 카테고리 수가 적은 경우 희소 행렬 생성 -> 데이터셋 크기가 커져 메모리, 처리 속도에 부담
- pd.get_dummies
X = pd.get_dummies(X_raw)
from sklearn.model_selection import train_test_split
# 0.2는 8:2, stratify = y 쪼갤 때 비슷하게 나뉘게 하는 것 -> 클래스 균형있게 나누기 위해
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2,
stratify = y, random_state = 42)* stratify를 번역할 때 `층화표집`이라고 번역하기도 함
- 이탈한다, 안 한다 2가지 값이 train, test 어느 한쪽으로 쏠리는 train은 이탈 데이터는 학습을 거의 못했는데 test는 대부분 이탈 데이터일 때 제대로 된 예측을 하지 못함
- 정답의 비율이 train, test가 비슷하게 나뉘도록 해주는 것이 `stratify = y` 의 기능
- class를 균형있게 나눠주면 학습과 예측에 도움이 된다
RandomForest로 예측
- n_estimators : int, default=100
: 숲에 있는 나무의 수
- criterion : {"gini", "entropy", "log_loss"}, default="gini"
: 분할의 품질을 측정하는 피처
- max_depth : int, default=None
: 트리의 최대 깊이
- min_samples_split : int or float, default=2
: 내부 노드를 분할하는 데 필요한 최소 샘플 수
- max_features : {“auto”, “sqrt”, “log2”}, int or float, default=”auto”
최상의 분할을 찾을 때 고려해야 할 피처의 수
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state = 42)
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
y_predict[:5]- 평가
(y_test == y_predict).mean()모델 평가
# feature_importances_ 를 통해 모델의 피처 중요도를 추출
# model.feature_importances_를 DataFrame으로 만들어 fi라는 변수에 할당
fi = pd.DataFrame(model.feature_importances_)
# fi 데이터프레임의 인덱스를 model.feature_names_in_으로 설정
fi.index = model.feature_names_in_
#model.feature_importances_로 데이터프레임을 만들어 주었을 때
#column의 이름을 따로 지정해주지 않아서 0, 1 로 생성
fi = fi.sort_values(by = 0)
# 피처 중요도를 시각화
fi.head(15).plot.barh()-> 랜덤 포레스트는 각각의 결정트리를 모두 표현하기 어려워서 시각화를 하지 않는다 -> 대신 feature importance를 통해 모델의 동작을 이해
- 파라미터 추가
model = RandomForestClassifier(random_state=42,
n_estimators=100,
# 나무의 갯수
max_features=0.9)
# 피처를 다 사용하는게 아니고 90퍼만 사용
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
(y_test == y_predict).mean()-> 오히려 떨어질 수도 있음
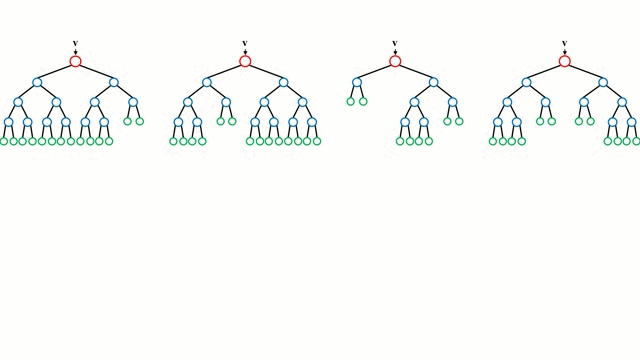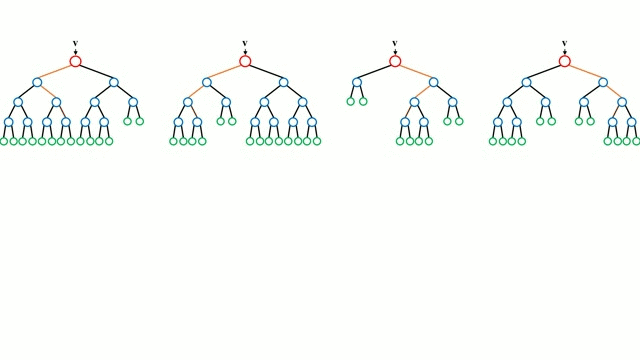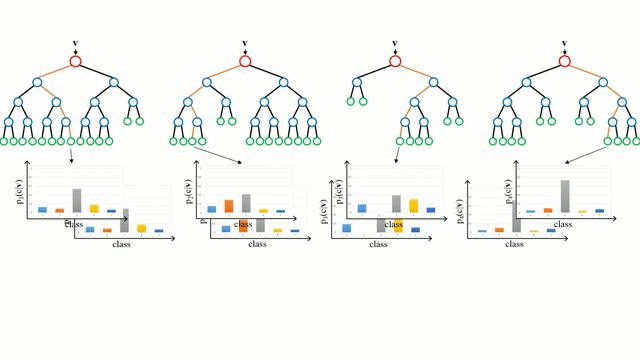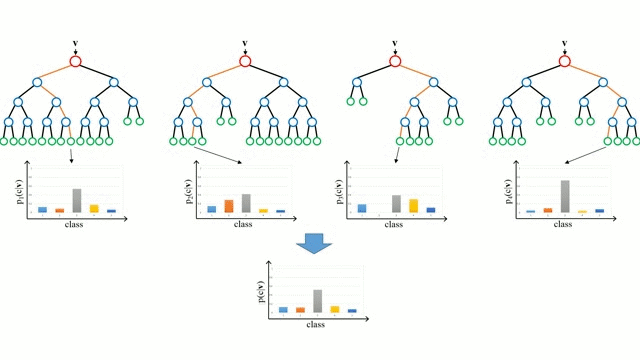
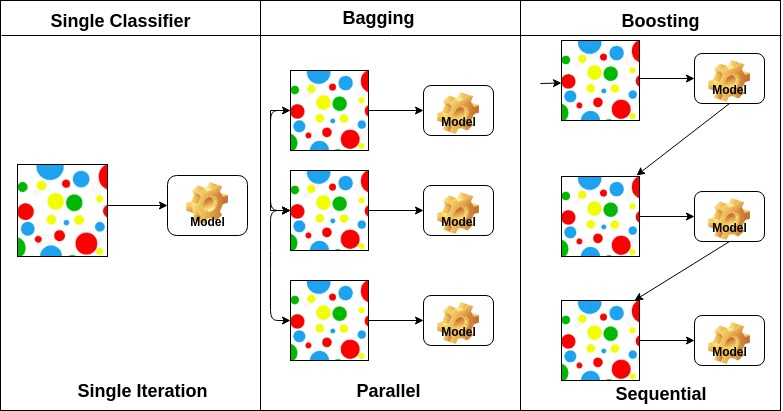
📎 앙상블이란?
: 머신러닝 위한 다양한 학습 알고리즘 결합하여 학습시키는 것 -> 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 등이 있음
📎 배깅(Bagging)
: bootstrap aggregating의 약자 / 부트스트랩을 집계 -> 병렬, 복원추출
배깅은 서로 다른 데이터셋들에 대해 훈련 시킴으로써, 트리들을 비상관화시켜 주는 과정
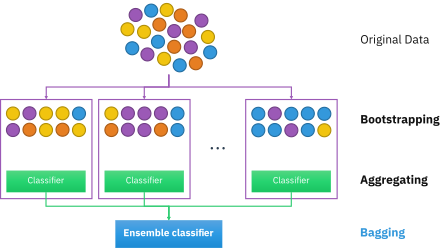
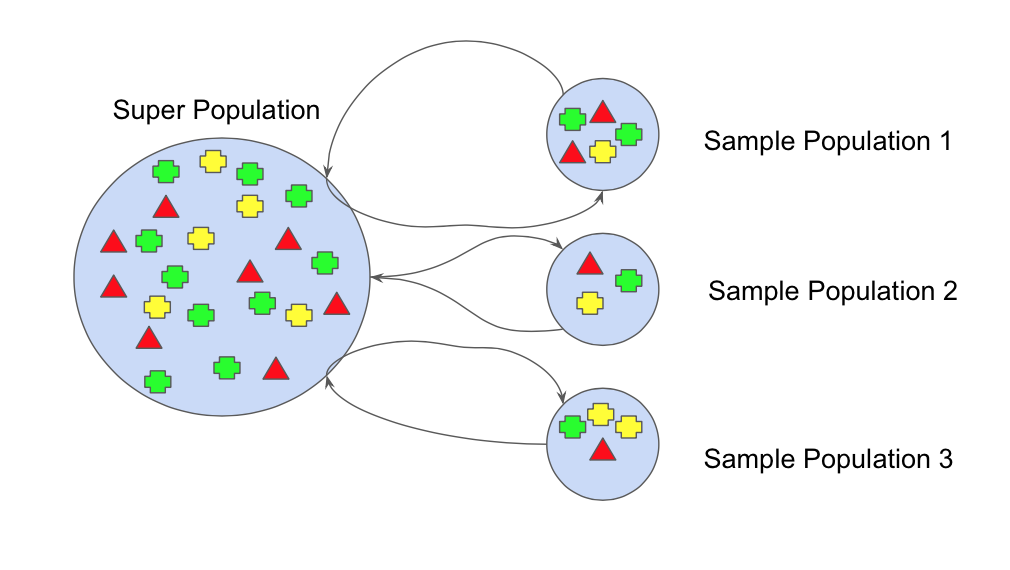
📎 부트스트랩(bootstrap)
: 부트스트랩이란, 주어진 훈련 데이터에서 중복을 허용하여 원 데이터셋과 같은 크기의 데이터셋을 만드는 과정
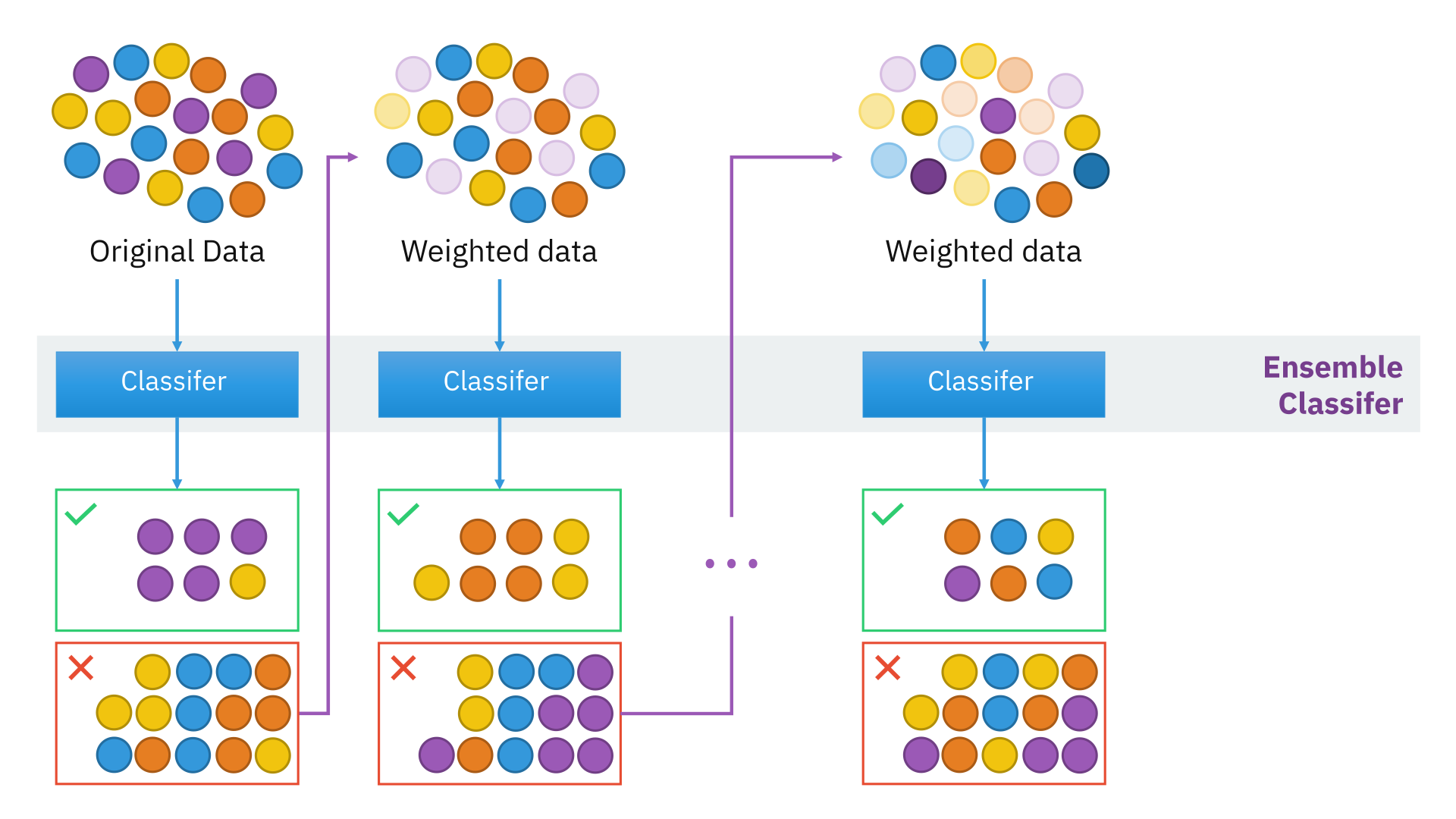
📎 부스팅(Boosting)
: 순차적, 복원추출로 가중치
부스팅 기법은 여러 얕은 트리를 연결하며 편향과 분산을 줄여 강력한 트리를 생성하는 기법
이전 트리에서 틀렸던 부분에 가중치를 주며 지속적으로 학습
'AI SCHOOL' 카테고리의 다른 글
| [ML] ExtraTreesRegressor / 회귀 모델 평가 지표(MAE, MSE, RMSE, r2_Score) (0) | 2023.03.18 |
|---|---|
| [ML] One hot Encoding / ExtraTreesClassifier / cross validation (0) | 2023.03.18 |
| [ML] Decision Tree (0) | 2023.03.17 |
| [ML] Clustering (0) | 2023.03.12 |
| [통계분석] 상관분석 / 회귀분석 (0) | 2023.02.16 |