멋사 AI SCOOL 7일차
: Python 기초
* Keywords
#class
#분산
#공분산
#상관계수
#결정계수
* Today I Learned
지난 시간 복습
- 반복되는 코드를 묶어서 사용 -> 코드의 유지보수 향상
- 사용법: 함수선언(코드작성) -> 함수호출(코드실행)
- def, return, argument, parameter, docstring, scope, global, lambda
- argument, parameter: 함수호출하는 코드에서 함수선언하는 코드로 데이터를 전달
- default parameter, keyword argument
- *args / **kwargs
- parameter: 여러개의 아규먼트 -> 하나의 변수(tuple, dict)로 묶어서 코드 실행
- argument: 하나의 변수(list, tuple, dict) -> 여러개 아규먼트로 풀어서 코드실행(함수 호출)
- return: 함수를 실행한 결과를 변수에 저장할 때 사용 / 함수의 코드 실행을 중단할 때 사용
- docstring: 함수 설명글 작성 : 함수를 선언하는 코드 바로 아래에 멀티라인 문자열로 작성 -> help() 사용해서 확인할 수 있음
- scope: 함수 안에서 선언(지역: local), 함수 밖에서 선언(전역: global)
- 지역영역에서 전역영역의 변수를 가져올 때: global
- 전역영역에서 지역영역의 변수를 가져올 때: return
- lambda: 일회성 함수 : 간단한 함수(파라미터, 리턴)를 함수 선언 없이 함수의 기능을 사용 가능
class
- 변수, 함수를 묶어서 코드 작성하는 방법
- 객체지향을 구현하는 문법 -> 객체지향: 실제 세계를 모델링하여 프로그램을 개발하는 개발 방법론 -> 협업을 용이하게 하기 위한
- 클래스 사용법
- 클래스 선언(코드작성) -> 객체생성(메모리 사용) -> 메서드 실행(코드실행)
- 클래스 선언(설계도 작성) -> 객체생성(제품 생산) -> 매서드 실행(기능 사용)
# 클래스 선언: 코드 작성
# 계산기 설계 : Calculator : number1, number2, plus(), minus()
class Calculator:
number1, number2 = 1, 2
def plus(self):
return self.number1 + self.number2
def minus(self):
return self.number1 - self.number2
#객체생성: 메모리 사용
calc1 = Calculator()
clac2 = Calculator()
#dir(): 객체에 들어가 있는 변수 출력
[var for var in dir(calc1) if var[0] != '_']
calc1.number1, calc1.number2(1, 2)
매서드 실행: 코드 실행
calc1.plus(), calc1.minus()(3, -1)객체의 변수 수정하려면 데이터 선택 = 수정할 데이터
-> calc1. number1 = 30
self: 객체 자신
사실 이 부분 이해 안됨 -> 일단 self가 자기 자신으로 이해함
스페셜 메서드
: 특별한 기능을 하는 메서드: 앞뒤로 __ 를 붙임
생성자 메서드 : __init__()
객체를 생성할 때 실해오디는 메서드
변수의 초기값을 설정할 때 주로 사용
불량 객체가 만들어질 확률을 줄여줌
class Account:
def __init__(self, balance):
self.balance = balance
def insert(self, amount):
self.balance += amount
def withdraw(self, amount):
if self.balance >= amount:
self.balance -= amount
else:
print(f'잔액이 {amount - self.balance}원 부족합니다.')클래스는 사용자 정의 데이터 타입
print([var for var in dir(data) if var[0] != '_'])데이터 타입 메서드 불러오기 -> but, 암기할 필요 없음
객체의 데이터 타입에 따라서 사용할 수 있는 변수, 메서드가 다르다
상속
: 다른 클래스의 변수(메서드)를 가져와서 사용하는 방법
# iPhone1 : call
# iPhone2 : call, send_msg
# iPhone3 : call, send_msg, internet

# 상속 사용
class iphone1:
def call(self):
print('calling')
class iphone2(iphone1):
def send_msg(self):
print('send_msg!')
class iphone3(iphone2):
def internet(self):
print('internet!')
다중상속
# 다중상속
class Human:
def walk(self):
print('walking!')
class Korean:
def eat(self):
print('eat kimchi!')
class Indian:
def eat(self):
print('eat curry!')# Human -> Korean -> Jin
# 똑같은 매서드 있으면 Korean
class Jin(Korean, Human):
def skill(self):
print('coding')다중 상속도 됨 순서는 뒤에서부터
그리고 똑같은 매서드 있으면 앞에잇는걸로 나타남
데코레이터 decorator
: 함수에서 중복되는 코드를 데코레이터 함수로 만들어 코드 작성하는 방법
원래 있던 함수에 새로운 기능을 추가한 함수로 변경할 때 주로 사용
def func1() :
print('code1')
print('code2')
print('code3')
def func2() :
print('code1')
print('code4')
print('code3')def deco(func) :
def wrapper(*args, **kwargs) : #함수 안에 함수 들어가서 지역 함수
print('code1')
func() # ==func1() : print('code2')
print('code3')
return wrapper# deco 함수의 파라미터 func에 func1이 들어감
# func1 함수는 deco 함수의 return 함수인 wrapper 함수로 변경
@deco
def func1():
print('code2')
@deco
def func2():
print('code4')
func1()
func2()
패스워드 데코리에터
# 패스워드를 맞춰야 함수의 실행이 가능하도록 하는 데코레이터 자성
def admin(func):
def wrapper(*args, **kwargs):
pw = input('insert password : ')
if pw == 'python': #패스워드 맞음
result = func(*args, **kwargs)
else: #패스워드 맞지 않음
result = 'wrong password!'
return result
return wrapperdef plus(n1, n2):
return n1 + n2
@admin
def minus(n1, n2):
return n1 - n2
minus(1,2)insert password : python
running time : 5.9952232837677 sec
-1-> 파이썬 코드로 함수 만들어서 사용하는 것 보다 근야 numpy 함수 사용하는 것이 훨씬 빠르다... 결론은...
분산
- 1개의 이산정도를 나타냄
- 편차 제곱의 평균
- 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자
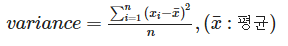
파이썬 함수
def variance(data):
var = 0
x_ = sum(data) / len(data)
for xi in data:
var += (xi - x_) ** 2
return var / len(data)variance(data1), variance(data2), variance(data3)(50.0, 126.0, 104.0)넘파이 함수
np.var(data1), np.var(data2), np.var(data3)-> %%time 해보면 np.var이 훨씬 빠름
공분산
- 2개의 확률변수의 상관정도를 나타냅니다.
- 평균 편차곱
- 방향성은 보여줄수 있으나 강도를 나타내는데 한계가 있습니다.
- 표본데이터의 크기에 따라서 값의 차이가 큰 단점이 있습니다.
- 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 선형 상관성이 있다면 양수의 공분산을 가진다.반대로 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값이 하강하는 선형 상관성을 보인다면 공분산의 값은 음수가 된다
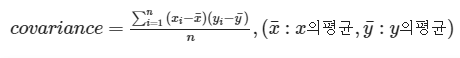
파이선 함수
def covariance(x,y):
cov = 0
x_ = sum(x) / len(x)
y_ = sum(y) / len(y)
for xi, yi in zip(x,y):
cov += (xi-x_) * (yi-y_)
return cov / (len(x)-1)
covariance(data1, data2), covariance(data1, data3)넘파이
np.cov(data1, data2)[0,1], np.cov(data1, data3)[0,1]상관계수
- 공분산의 한계를 극복하기 위해서 만들어집니다.
- -1 ~ 1까지의 수를 가지며 0과 가까울수록 상관도가 적음을 의미합니다.
- x의 분산과 y의 분산을 곱한 결과의 제곱근을 나눠주면 x나 y의 변화량이 클수록 0에 가까워집니다.

파이썬 함수
def covariance(x, y):
cov, x_, y_ = 0, sum(x) / len(x), sum(y) / len(y)
for xi, yi in zip(x, y):
cov += (xi - x_) * (yi - y_)
return cov / len(x)
def cc(x, y):
cov = covariance(x, y)
var = (variance(x) * variance(y)) ** 0.5
return cov / var
cc(data1, data2), cc(data1, data3)결정계수
- x로부터 y를 예측할수 있는 정도
- 상관계수의 제곱 (상관계수를 양수화)
- 수치가 클수록 회기분석을 통해 예측할수 있는 수치의 정도가 더 정확
cc(data1, data2)**2 , cc(data1, data3)**2
*결론
- 공분산 : 방향성 o, 강도x
- 상관계수 : 방향성 o, 강도o
- 결정계수 : 방향성 x, 강도o
* Homework
* Reference
https://www.youtube.com/watch?v=h-OwxPqjMpc&list=PL7ZVZgsnLwEEdhCYInwxRpj1Rc4EGmCUc&index=9
* Retrospective
😍 Liked
어느 부분이 부족한지 알 수 있음
그래도 부분 부분 이해를 하긴 함
📚 Learned
TIL
💦 Lacked
전체적으로...
이전에 공부할 때 파이썬은 기초만 하고 바로 pandas, numpy를 공부해서 이 부분이 약한 것을 알고(물론 지금 하는 것도 기초라면 기초겠지) 있었지만 이정도였다니...
🙏 Longed for
어쩌겠어 해야지
마냥 기초 함수는 아닌 것 같다. 짧은 시간에 많은 것을 배우는데 쉬운 것도 이상 -> 일단 파이썬 함수 전체적으로 훑을 필요가 있음
파이썬 문제보다는 일단 내용을 이해하는 것이 우선 그러고 백준문제 풀기
'AI SCHOOL > TIL' 카테고리의 다른 글
| [TIL] 멋사 AI SCOOL DAY 9 - 데이터사이언스 개요, 판다스(pandas) (0) | 2023.01.09 |
|---|---|
| [TIL] 멋사 AI SCOOL DAY 9 - 파이썬 클래스, 모듈, 패키지, 예외 처리 (0) | 2023.01.06 |
| [TIL] 멋사 AI SCOOL DAY 7 - 파이썬 함수 (0) | 2023.01.04 |
| [TIL] 멋사 AI SCOOL DAY 6 - 연산자, 조건문, 반복문 (1) | 2023.01.03 |
| [TIL] 멋사 AI SCOOL DAY 5 - 프로그래밍 개요, 변수 선언, 데이터 타입 (0) | 2023.01.02 |